

În două articole anterioare din ziarul Electronica azi am prezentat standardul JPEG, standard folosit pentru comprimarea imaginilor statice. În acest articol şi în cele ce vor urma voi prezenta conceptele de bază care definesc standardul MPEG, folosit pentru compresia imaginilor dinamice, adică a secvenţelor video. Deşi problematica este întrucâtva asemănătoare cu cea prezentată la compresia JPEG, procesul este mult mai complex din două motive destul de simple şi anume: cantitate imensă de informaţie cuprinsă în imaginea video precum şi necesitatea ca acest proces de compresie să se desfăşoare în timp real.
MPEG este considerat standardul revoluţiei audio-video digitale. Acest standard a apărut ca un răspuns la necesitatea de a comprima cât mai bine imaginea şi sunetul. Există trei subseturi de standarde în familia MPEG şi anume: MPEG-1, MPEG-2 şi MPEG-4. Primele două sunt operaţionale, iar ultimul deşi este implementat va suferi probabil unele modificări în sensul perfecţionării acestuia. Voi prezenta câteva informaţii necesare unei cunoaşteri sumare pentru fiecare din cele trei standarde, urmând să fac o prezentare amănunţită a algoritmului de compresie şi decompresie pentru standardul MPEG-1, deoarece acesta conţine principiile şi metodele de bază, reluate într-o formă dezvoltată în celelalte două standarde.
MPEG-1 (ISO/IEC 11172) a apărut din nevoia unui format comun pentru secvenţele video şi audio comprimate pe mediile de stocare ca: CD (Compact Disc), DAT (Digital Audio Tape), discuri magnetice şi optice. Prin MPEG-1 secvenţele video şi audio sunt manipulate de calculatoare ca orice fel de date numerice, pot fi stocate, transmise, refăcute, afişate, etc. Imaginile şi sunetele sunt transformate într-un şir de date, bine definit. MPEG-1 se foloseşte pentru rezoluţii de 352 x 240 la 30Hz sau 352 x 288 la 25Hz, iar codarea se face pentru o viteză de transmitere de 1,5 Mbit/sec. care corespunde la rata de transfer CD-ROMx1.
MPEG-2 (ISO/IEC 13818) este o generalizare a lui MPEG-1, comprimă şi imaginile întreţesute, este mult mai elaborat şi are mai multe componente. Conţine proceduri de control, testare şi identificare. În partea de video are rezoluţie mai bună, s-a ajuns la 10 biţi pe pixel, în loc de 8 biţi pe pixel cât are MPEG-1.
MPEG-4 este organizat ca o colecţie de obiecte audio şi video, naturale şi sintetice. Este mai apropiat de limbaje de programare orientate pe obiect, este foarte sofisticat.
În continuare voi prezenta algoritmul de lucru al standardului MPEG-1 şi voi face acest lucru urmărind două scopuri: să descriu toţi paşii invocaţi în standardul MPEG-1 şi să prezint sintaxa acestuia. Nu voi trata toate detaliile din standard întrucât acest lucru nu este necesar. Standardul MPEG-1 defineşte un format pentru semnalul video numeric comprimat, capabil să susţină o rată a datelor de 1856 Kb/s. Dacă adăugăm şi o încărcare de 128Kb/s pentru canalul audio, rezultă necesitatea unui canal de telecomunicaţii cu o lărgime de bandă de 1984 Kb/s pentru transmiterea unui canal de televiziune.
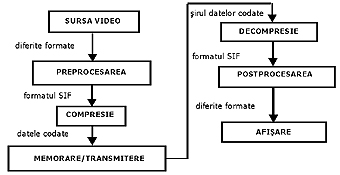
În figura 1 se prezintă structura generală a algoritmului de prelucrare a semnalului video de la sursa primară, care este de cele mai multe ori o cameră de luat vederi, până la destinaţie, care este de cele mai multe ori un monitor TV. Fiecare din etapele algoritmului va fi prezentată în continuare, mai mult sau mai puţin dezvoltat, în funcţie de legătura acesteia cu procesul de compresie şi decompresie a imaginii. Standardul nu defineşte în amănunt întregul proces de compresie şi decompresie algoritmică a semnalului TV, ci descrie, într-un mod simplu, sintaxa canalului codat de date şi paşii utilizaţi în procesul de compresie. Din acest motiv standardul permite o mare flexibilitate a modului în care datele primare vor fi comprimate.
Sursa video
Există o mulţime de surse video. Acestea sunt stabilite prin standarde, atât din punct de vedere al structurii semnalelor cât şi al parametrilor acestora. Pentru televiziunea digitală există standardul internaţional CCIR 601. Semnalul TV în acest standard poate constitui sursa primară de intrare în algoritmul de lucru. Semnalul TV conform acestui standard conţine trei componente şi anume: o componentă de luminanţă, Y şi două componente de crominanţă, U şi V. Componenta Y reprezintă imaginea alb-negru, iar U şi V imaginea color. Imaginea numerică este caracterizată de două mărimi şi anume: frecvenţa imaginilor (picture rate) şi frecvenţa pixelilor (pixel aspect ratios). Vom considera în exemplele ce urmează frecvenţa imaginilor 30 cadre/sec. şi o rezoluţie spaţială de 720 x 486 pixeli de luminanţă. Cantitatea de informaţii numerice (720 x 486 pixeli x 30 cadre/sec. x 2 componente/pixel x 1octet/componentă = 20.02 MB/sec.) este prea mare pentru a fi transmisă pe un canal de telecomunicaţii de 1,5 Mb/s cât este prevăzut în standardul MPEG-1 şi de aceea este necesară o preprocesare a semnalului de la aceast tip de sursă.
Preprocesarea datelor sursă
Preprocesarea urmăreşte mai multe scopuri, dar cel mai important este reducerea lărgimii de bandă. MPEG-1 este definit numai pentru format neîntreţesut, deci preprocesarea trebuie să includă conversia din format întreţesut în format neîntreţesut. De obicei sursa originală este redusă la un format sursă de intrare SIF (Source Input Format), care constă în formatul 360 x 240 pixeli, iar înjumătăţirea cantităţii de informaţie se face prin renunţarea la fiecare al doilea semicadru. Aceasta poate să producă efecte de aliere (efecte ale afişării semnalelor de înaltă frecvenţă ca semnale de joasă frecvenţă determinate de eşantionarea imperfectă). Există metode sofisticate de rezolvare a acestei probleme, dar sunt foarte scumpe şi nu ne propunem să le prezentăm în acest material. Se pot uşor înjumătăţi rezoluţiile (orizontală şi verticală) prin filtrare şi subeşantionare. O abordare similară se poate folosi pentru componentele de culoare U şi V. Aceşti paşi nu sunt definiţi în standard şi nu vor fi analizaţi în detaliu în cele ce urmează. În final rezultă un format video cu 30 cadre pe secundă, o rezoluţie de 360 x 240 pixeli de luminanţă, 180 x 120 pixeli de culoare U şi 180 x 120 pixeli de culoare V. Standardul MPEG-1 nu face restricţii la rezoluţia de bit, număr cadre sau rata de bit. În tabelul 1 se prezintă constrângerile impuse de standardul MPEG-1.
PARAMETRII ŞIRULUI DE BIŢI VALORI
Rezoluţie orizontală 768 sau mai mic
Rezoluţie verticală 576 sau mai mic
Nr.de macroblocuri pe imagine 396 sau mai mic
Nr. de macroblocuri pe secundă 99.000 sau mai mic
Rata de bit 1,86 Mb/s sau mai mic
Imagini pe secundă 30 sau mai mic
Mărimea bufferului decodor 376.832 biţi sau mai mic
Pentru a înţelege mai uşor modul de lucru al algoritmului de compresie MPEG-1, voi prezenta mai întâi conceptul de structurare ierarhică a datelor, adică modul în care se ajunge de la o secvenţă de imagini la pixel, care este elementul informaţional elementar de imagine. Se utilizează noţiunea de pixel video ca fiind un pixel al imaginii originale şi pixeli componenţi care sunt componentele informaţionale elementare cu care se operează în procesul de compresie. Astfel un grup de 2 x 2 pixeli video constau din: 2 x 2 pixeli componenţi de luminanţă, un pixel component de crominanţă U şi un pixel component de crominanţă V.
Astfel, formatul SIF (Source Input Format) conţine 360 x 240 pixeli componenţi de luminanţă, 180 x 120 pixeli componenţi de crominanţă U şi 180 x 120 pixeli de crominanţă V. Pixelii componenţi sunt descrişi printr-un singur octet de date. Unitatea video fundamentală în procesul de compresie este macroblocul. Un macrobloc este un grup de 16 x 16 pixeli video. Deci macroblocul este format din 16 x 16 pixeli de luminanţă şi două blocuri de 8 x 8 pixeli de crominanţă. Termenul de bloc defineşte un număr de 8 x 8 pixeli componenţi. 16 x 16 pixeli de luminanţă sunt împărţiţi în patru blocuri, astfel că macroblocul va conţine 6 blocuri de 8 x 8 pixeli componenţi. Această structurare ierarhică a datelor este prezentată în figura 2
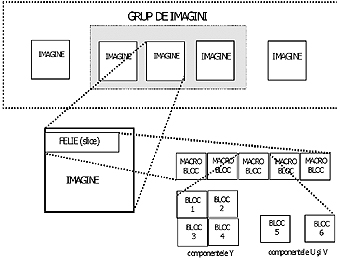
.
Vom face în continuare o scurtă incursiune în modul cum sunt percepute şi definite imaginile într-un proces de codare MPEG. Deşi la prima vedere toate imaginile sunt la fel ca mărime şi ca număr de pixeli totuşi din punct de vedere al rolului pe care îl joacă în procesul de codare există mai multe tipuri de imagini. Din acest punct de vedere imaginile video pot fi:
• imagini interne (intra pictures), numite în continuare, de tip i;
• imagini predicţionate (predicted pictures), numite în continuare, de tip p;
• imagini predicţionate bidirecţional (bidirectionally predicted pictures), numite în continuare, de tip b;
• imagini DC (d – pictures).
Predicţia se bazează numai pe corelaţia temporală între cadre succesive, adică unele porţiuni de cadre pot să nu difere de altele pentru perioade scurte de timp.
Metodele de compresie şi decompresie diferă pentru fiecare tip de imagine.
Metodele mai simple sunt utilizate pentru imagini de tip i urmate de imaginile predicţionate, de tip p, şi apoi de cele predicţionate bidirecţional, de tip b. Vom examina pe rând compresia şi decompresia pentru fiecare tip de imagine. Imaginile de tip i descriu complet un singur cadru, fără referire la alt cadru. Este asemănător cu ceea ce am prezentat la compresia JPEG, şi acolo o imagine era comprimată utilizând numai propriile informaţii. Imaginile predicţionate, de tip p, se bazează pe imaginile de tip i şi pe cele de tip p anterioare. Referirea se face de la o imagine i sau p anterioară la o imagine p viitoare şi de aceea ea se numeşte predicţie viitoare. Imaginile b se predicţionează din cea mai apropiată imagine i sau p anterioară şi din cea mai apropiată imagine i sau p posterioară. Referirea la o imagine viitoare (una care nu a fost încă afişată) este denumită predicţie spre înapoi. În timp ce predicţia spre înainte este intuitivă (prevede o imagine viitoare bazată pe imaginea anterioară), predicţia spre înapoi nu este intuitivă. Toate cele trei tipuri de imagini sunt ilustrate în figura 3.
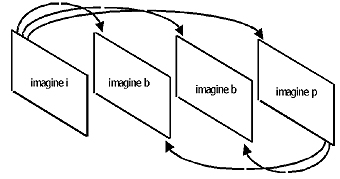
Săgeţile arată care imagine este utilizată pentru predicţie.
Există şi al patrulea tip de imagine cunoscută sub denumirea de imagine de tip d. Acestă imagine conţine informaţii de joasă frecvenţă şi este utilizată pentru implementarea playback-ului rapid, spre înainte, de calitate redusă. Imaginea de tip b realizează cea mai mare compresie, dar introduce şi cele mai multe erori. Pentru a elimina erorile de propagare, imaginea de tip b nu trebuie să fie predicţionată din altă imagine de tip b. Imaginile de tip p introduc puţine erori şi realizează o compresie scăzută. Imaginea de tip i produce cea mai mică compresie, dar şi cea mai bună calitate a imaginii. Aceste imagini permit puncte de intrare cu acces aleatoriu în secvenţa video. Standardul MPEG-1 nu specifică nici o distribuţie particulară care formează o secvenţă referitoare la cele patru tipuri de imagini. El permite în schimb diferite distribuţii ale acestora pentru a oferi diferite grade de compresie şi de accesibilitate aleatoare. Într-o distribuţie obişnuită trebuie să existe imagini de tip i la fiecare 1/2 secunde şi două imagini de tip p între imagini i sau p succesive. La 30 de semicadre pe secundă secvenţa imaginilor este arătată în figura 4.
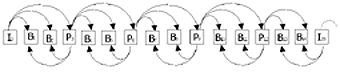
Indicii numerotează imaginile în ordinea afişării. De reţinut este faptul că pentru a decoda imaginile de tip p, imaginile de tip i anterioare trebuie să fie disponibile. În mod similar, pentru a decoda imaginile de tip b, imaginile p viitoare şi anterioare sau imaginile i trebuie să fie disponibile. De exemplu: pentru a decoda imaginea B1 trebuie să aveam deja decodată imaginea I0 şi P3. Deci este necesar ca imaginea P3, care în secvenţa video ocupă poziţia a doua după secvenţa video B1, să fie transmisă înaintea imaginii B1. Prin urmare, în şirul numeric al unui canal codat MPEG, ordinea imaginilor este alta decât cea normală, pe care o vedem la afişare.
Porţiuni din imagine pot fi predicţionate din alte imagini cu mare acurateţe, în timp ce altele nu pot fi predicţionate. Din acest motiv, macroblocul din interiorul unei imagini de tip p nu este necesar să fie codat prin predicţie dintr-o imagine anterioară. Acesta poate fi codat ca o unitate independentă în acelaşi mod ca şi o imagine de tip i. Similar, macroblocurile dintr-o imagine de tip b pot fi codate în acelaşi mod ca în imaginile de tip i sau p. Astfel se poate realiza o rată mare de compresie, dar se complică algoritmul de codare.
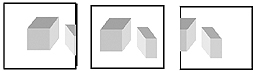
În figura 5 se ilustrează cele afirmate mai sus, cu un exemplu obişnuit şi anume o filmare spre dreapta.
Macroblocurile din marginea stângă a imaginii curente (imaginea curentă fiind cea din mijloc) pot fi predicţionate înapoi din imaginea anterioară. Aşadar macroblocurile pot reprezenta aceeaşi imagine din imaginea anterioară, dar deplasate spre stânga cu un anumit număr de pixeli. Similar, macroblocurile din partea dreaptă a imaginii nu pot fi predicţionate din imaginea anterioară deoarece aceasta nu este prezentă în imagine, dar imaginea este prezentă în imaginile următoare astfel că putem utiliza imaginile următoare pentru predicţie, adică predicţionarea înainte.
Ing. Toader Melinte
S.C.Seektron S.R.L
Tel. 0244-185920
melin@xnet.ro
www.seektron.ro