


Democratizarea AI ridică noi provocări pentru proiectanții de sisteme embedded
Acest articol analizează modul în care democratizarea AI generează noi provocări pentru proiectanții de sisteme embedded, care urmăresc să dezvolte aplicații de tip “ML la margine” (ML at the edge), capabile să funcționeze eficient, respectând în același timp cerințele privind încărcarea procesorului și spațiul de stocare, precum și constrângerile stricte de consum energetic specifice dispozitivelor IoT.
De la supraveghere și controlul accesului până la fabrici inteligente și întreținere predictivă, implementarea inteligenței artificiale (AI) bazate pe modele de învățare automată (ML) devine omniprezentă în aplicațiile industriale de procesare la margine din domeniul IoT. Odată cu această extindere, dezvoltarea soluțiilor bazate pe AI s-a “democratizat”, trecând de la o disciplină specifică cercetătorilor în domeniul datelor la una pe care proiectanții de sisteme embedded trebuie să o stăpânească.
Provocarea acestei democratizări constă în faptul că proiectanții nu sunt întotdeauna pregătiți să definească corect problema care trebuie rezolvată și să colecteze și să organizeze datele în mod adecvat. În plus, spre deosebire de aplicațiile orientate către consumatori, există puține seturi de date disponibile pentru implementările AI industriale, ceea ce înseamnă că acestea trebuie adesea create de la zero, pornind de la datele proprii ale utilizatorului.
AI în utilizarea curentă
Inteligența artificială (AI) a devenit o parte integrantă a vieții cotidiene, iar învățarea profundă și învățarea automată (DL și, respectiv, ML) stau la baza multor aplicații considerate astăzi firești, precum procesarea limbajului natural, viziunea computerizată, întreținerea predictivă și analiza datelor.
Primele implementări ale AI se bazau pe cloud sau pe servere, necesitând o putere de procesare și o capacitate de stocare considerabile, precum și o lățime de bandă mare între aplicația AI/ML și periferie (punctul final). Deși astfel de configurații rămân necesare pentru aplicații de tip AI generativ, precum ChatGPT, DALL·E și Bard, în ultimii ani a apărut AI-ul procesat la margine, unde datele sunt prelucrate în timp real la punctul de captare.
Procesarea la margine reduce considerabil dependența de cloud, face sistemul sau aplicația mai rapidă, necesită mai puțină energie și reduce costurile. Mulți consideră, de asemenea, că securitatea este îmbunătățită; mai corect spus, accentul se mută de la protejarea comunicațiilor în timpul transferului între cloud și terminal la securizarea dispozitivului de la margine.
AI/ML la margine pot fi implementate pe un sistem embedded tradițional, în care proiectanții au acces la microprocesoare performante, unități de procesare grafică și o gamă largă de dispozitive de memorie – resurse comparabile cu cele ale unui PC. Cu toate acestea, există o cerere în creștere pentru dispozitive IoT (comerciale și industriale) care să integreze AI/ML la margine, iar acestea dispun, de regulă, de resurse hardware limitate și, în multe cazuri, sunt alimentate de baterii.
Potențialul AI/ML la margine, rulate pe hardware cu resurse și consum de putere limitate, a condus la apariția termenului TinyML. Există numeroase exemple de utilizare în industrie (de exemplu, pentru întreținere predictivă), automatizarea clădirilor (monitorizarea mediului), construcții (supravegherea siguranței personalului) și securitate.
Fluxul de date
AI (și, prin extensie, subcategoria sa ML) necesită un flux de lucru care începe cu colectarea datelor și se încheie cu implementarea modelului (Figura 1). În cazul TinyML, optimizarea fiecărei etape a acestui flux este esențială, din cauza resurselor limitate ale sistemelor embedded.
De exemplu, cerințele de resurse pentru TinyML includ frecvențe de procesare cuprinse între 1 și 400 MHz, 2 până la 512 KB de RAM și 32 KB până la 2 MB de memorie Flash. În plus, funcționarea într-un buget energetic de numai 150 µW până la 23,5 mW reprezintă adesea o provocare.

Figura 1: Flux de lucru AI simplificat. Deși nu este ilustrat, etapa de implementare a modelului poate furniza la rândul său date înapoi în flux, influențând chiar și procesul de colectare a datelor. (Sursa: Microchip)
Mai important însă este compromisul inerent integrării AI într-un sistem embedded cu resurse limitate. Modelele sunt esențiale pentru comportamentul sistemului, dar proiectanții trebuie adesea să echilibreze calitatea și precizia modelului – care influențează fiabilitatea și siguranța – cu performanța sistemului, în special viteza de execuție și consumul de energie.
Un alt factor cheie îl reprezintă alegerea tipului de algoritm AI/ML utilizat. În general, există trei categorii principale: algoritmi supravegheați, nesupravegheați și algoritmi de învățare prin întărire (bazată pe recompense și penalizări).
Soluții
Chiar și proiectanții care au o bună înțelegere a tehnologiilor AI și ML pot întâmpina dificultăți în optimizarea fiecărei etape a fluxului de lucru AI/ML și în găsirea echilibrului optim între precizia modelului și performanța sistemului. În aceste condiții, cum pot proiectanții de sisteme embedded fără experiență anterioară să facă față acestor provocări?
În primul rând, este important de reținut că modelele implementate pe dispozitive IoT cu resurse limitate sunt eficiente atunci când au dimensiuni reduse, iar sarcina AI este limitată la rezolvarea unei probleme bine definite.
Din fericire, apariția ML (și în special a TinyML) în domeniul sistemelor embedded a condus la dezvoltarea unor medii de dezvoltare integrate (IDE), instrumente software, arhitecturi și modele – multe dintre acestea fiind open source. De exemplu, TensorFlow™ Lite pentru microcontrolere (TensorFlow Lite Micro) este o bibliotecă software gratuită, open source, destinată aplicațiilor ML și AI. Aceasta a fost creată pentru implementarea ML pe dispozitive cu doar câțiva kiloocteți de memorie. De asemenea, aplicațiile pot fi dezvoltate în Python, un limbaj open source și gratuit.
În ceea ce privește IDE-urile, MPLAB® X de la Microchip este un exemplu relevant. Acest mediu poate fi utilizat împreună cu MPLAB® ML, un plug-in pentru MPLAB X dezvoltat special pentru generarea de cod optimizat destinat aplicațiilor AI IoT bazate pe senzori. Bazat pe AutoML, MPLAB ML automatizează întregul flux de lucru AI/ML, eliminând necesitatea dezvoltării manuale a modelelor repetitive și consumatoare de timp. Procesele de extragere a caracteristicilor, antrenare, validare și testare conduc la obținerea unor modele optimizate, care respectă constrângerile de memorie ale microcontrolerelor și microprocesoarelor, permițând dezvoltatorilor să creeze și să implementeze rapid soluții ML pe platforme pe 32 de biți bazate pe Arm® Cortex® de la Microchip.
În flux
Sarcinile de optimizare a fluxului de lucru pot fi simplificate prin utilizarea unor seturi de date și modele existente. De exemplu, dacă un dispozitiv IoT compatibil cu învățarea automată (ML) necesită recunoașterea imaginilor, este recomandat să se pornească de la un set de date existent, format din imagini statice și secvențe video etichetate, utilizate pentru antrenarea, testarea și evaluarea modelului. De reținut că datele etichetate sunt necesare pentru algoritmii de învățare automată supravegheată.
Există deja numeroase seturi de date de imagini pentru aplicații de viziune computerizată. Totuși, deoarece sunt destinate aplicațiilor bazate pe PC, server sau cloud, acestea tind să fie de dimensiuni mari. ImageNet, de exemplu, conține peste 14 milioane de imagini adnotate.
În funcție de aplicația de învățare automată, pot fi necesare doar anumite subseturi de date; de exemplu, un număr mare de imagini cu persoane, dar doar câteva cu obiecte neînsuflețite. De pildă, în cazul utilizării unor camere cu funcții de învățare automată pe un șantier de construcții, sistemul poate declanșa o alarmă dacă o persoană care nu poartă cască de protecție intră în câmpul vizual. Modelul va trebui antrenat folosind, de regulă, un set limitat de imagini relevante – persoane cu sau fără cască de protecție. Cu toate acestea, poate fi necesar un set de date mai extins pentru a acoperi diferite tipuri de echipamente de protecție pentru cap și variații ale condițiilor de iluminare.
Disponibilitatea datelor de intrare
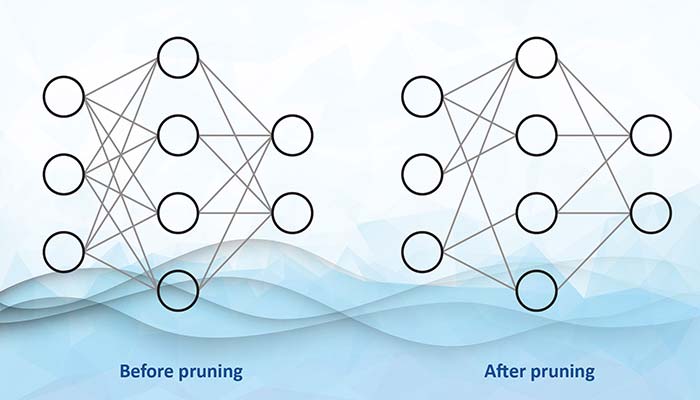
Figura 2: Tăierea (pruning) reduce densitatea rețelei neurale. În exemplul de mai sus, ponderea unor conexiuni dintre neuroni a fost setată la zero. Deși nu este ilustrat, și neuronii pot fi uneori eliminați prin pruning. (Sursă: Microchip)
Disponibilitatea datelor de intrare în timp real și a seturilor de date adecvate, pregătirea datelor și antrenarea modelului corespund pașilor 1–3 din figura 1. Optimizarea modelului (pasul 4) este, de obicei, un proces de compresie care contribuie la reducerea cerințelor de memorie (RAM în timpul execuției și memorie nevolatilă pentru stocare), precum și a latenței de procesare.
Procesarea
În ceea ce privește procesarea, numeroși algoritmi AI, precum rețelele neurale convoluționale (CNN), întâmpină dificultăți atunci când modelele devin complexe. O tehnică populară de compresie este tăierea (pruning) (vezi figura 2), care poate fi clasificată în mai multe tipuri, inclusiv tăierea ponderilor, tăierea neuronilor și tăierea iterativă.
Cuantificarea este o altă tehnică populară de compresie. Aceasta constă în conversia datelor dintr-un format de înaltă precizie, cum ar fi reprezentarea în virgulă mobilă pe 32 de biți (FP32), într-un format cu precizie mai redusă, de exemplu un număr întreg pe 8 biți (INT8). Utilizarea modelelor cuantificate (vezi figura 3) poate fi integrată în procesul de antrenare în două moduri principale:
- Cuantificarea post-antrenare implică utilizarea unui model antrenat, de regulă în format FP32, care este ulterior cuantificat pentru implementare. De pildă, TensorFlow standard poate fi utilizat pentru antrenarea și optimizarea inițială a modelului pe un PC. Modelul este apoi cuantificat și, prin TensorFlow Lite, implementat pe dispozitivul IoT.
- Antrenarea conștientă de cuantificare (quantization-aware training) emulează efectele cuantificării în timpul antrenării, generând un model pe care instrumentele ulterioare îl pot transforma direct în variante cuantificate.
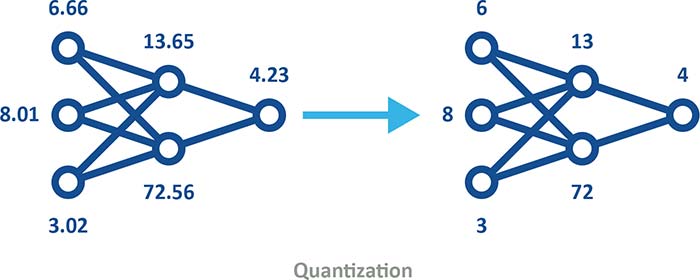
Figura 3: Modelele cuantificate utilizează o precizie mai mică, reduc cerințele de memorie și stocare și îmbunătățesc eficiența energetică, fără a modifica structura modelului. (Sursă: Microchip)
Deși cuantificarea este utilă, utilizarea excesivă poate duce la degradarea performanței. Procesul poate fi comparat cu compresia unei imagini digitale prin reducerea numărului de biți utilizați pentru reprezentarea culorilor și/sau a rezoluției — există un punct dincolo de care imaginea devine dificil de interpretat.
Concluzie
Așa cum am menționat în introducere, AI este deja o realitate în domeniul sistemelor embedded. Totuși, această democratizare înseamnă că inginerii proiectanți care, până nu demult, nu aveau nevoie să înțeleagă AI și ML se confruntă acum cu provocarea de a implementa astfel de soluții în propriile proiecte.
Deși dezvoltarea aplicațiilor ML, în condițiile valorificării eficiente a resurselor hardware limitate, poate părea descurajantă, aceasta nu reprezintă o provocare nouă – cel puțin nu pentru proiectanții experimentați de sisteme embedded. Un avantaj important îl reprezintă numeroasele resurse disponibile în comunitatea de ingineri, inclusiv materiale de instruire și instrumente, cum ar fi MPLAB® X, generatoare de modele de tip MPLAB® ML și seturi de date și modele open source.
Acest ecosistem permite inginerilor, indiferent de nivelul de experiență, să accelereze dezvoltarea soluțiilor AI și ML, care pot fi acum implementate inclusiv pe microcontrolere de 16 biți și chiar de 8 biți.
Despre autor
 Yann LeFaou este director asociat al diviziei de tehnologii tactile și de gesturi din cadrul Microchip. În această funcție, coordonează o echipă care dezvoltă tehnologii tactile capacitive și conduce inițiativele companiei în domeniul învățării automate (ML) pentru microcontrolere și microprocesoare. De-a lungul carierei sale la Microchip, a ocupat diverse funcții tehnice și de marketing, inclusiv responsabilități globale în domeniul tehnologiilor tactile capacitive, al interfețelor om-mașină și al electrocasnicelor. Yann LeFaou este absolvent al ESME Sudria din Franța.
Yann LeFaou este director asociat al diviziei de tehnologii tactile și de gesturi din cadrul Microchip. În această funcție, coordonează o echipă care dezvoltă tehnologii tactile capacitive și conduce inițiativele companiei în domeniul învățării automate (ML) pentru microcontrolere și microprocesoare. De-a lungul carierei sale la Microchip, a ocupat diverse funcții tehnice și de marketing, inclusiv responsabilități globale în domeniul tehnologiilor tactile capacitive, al interfețelor om-mașină și al electrocasnicelor. Yann LeFaou este absolvent al ESME Sudria din Franța.
Glosar de termeni
Învățare prin întărire (Reinforcement Learning – RL) – Metodă de învățare automată în care un model AI învață să ia decizii prin interacțiunea cu un mediu, pe baza unui sistem de recompense și penalizări. Scopul este maximizarea unei funcții de recompensă, prin identificarea unei strategii optime de acțiune în timp.
Set de date etichetat (Labeled Dataset) – Colecție de date în care fiecare exemplu este asociat cu un rezultat corect (etichetă), utilizată în învățarea supravegheată pentru antrenarea modelelor.
Învățare automată supravegheată (Supervised Learning) – Metodă de antrenare în care modelul învață pe baza unor date etichetate, corelând intrările cu rezultatele așteptate.
CNN (Rețea neurală convoluțională) – Tip de rețea neurală utilizată în special pentru procesarea imaginilor, capabilă să extragă automat caracteristici relevante din date vizuale.
Flux de lucru AI/ML (AI/ML Workflow) – Succesiunea etapelor necesare dezvoltării unui model: colectarea datelor, pregătirea acestora, antrenarea, validarea, optimizarea și implementarea.
Validare și testare – Etape prin care performanța modelului este evaluată pe date diferite de cele utilizate la antrenare, pentru a verifica generalizarea.
Pruning (tăiere) – Tehnică de optimizare care reduce complexitatea unui model prin eliminarea conexiunilor sau neuronilor cu impact redus, diminuând astfel consumul de resurse.
Cuantificare (Quantization) – Procesul de reducere a preciziei numerice a datelor (ex. FP32 → INT8) pentru a scădea cerințele de memorie și consumul energetic, cu un impact controlat asupra preciziei.
Cuantificare post-antrenare – Aplicarea cuantificării după finalizarea antrenării modelului, fără modificarea procesului de training.
Antrenare conștientă de cuantificare (Quantization-Aware Training) – Metodă în care efectele cuantificării sunt simulate în timpul antrenării, pentru a obține modele mai robuste după conversie.
AutoML – Tehnologie care automatizează etapele dezvoltării modelelor ML (selectarea algoritmilor, antrenare, optimizare), reducând intervenția manuală.
TensorFlow Lite Micro – Bibliotecă optimizată pentru rularea modelelor ML pe microcontrolere cu resurse limitate.