


Conversia hardware a rețelelor neurale convoluționale
În această serie de trei articole au fost prezentate proprietățile și aplicațiile rețelelor neurale convoluționale (CNN), utilizate în principal pentru recunoașterea modelelor și clasificarea obiectelor. În această parte finală este analizată conversia hardware a unei rețele CNN și avantajele utilizării unui microcontroler cu inteligență artificială (AI) integrând un accelerator CNN dedicat – o soluție care permite implementarea aplicațiilor AI la marginea Internetului Lucrurilor (IoT).
Articolele anterioare din serie sunt:
“Introducere în rețelele neurale convoluționale: Ce este învățarea automată? – Partea 1”
“Instruirea rețelelor neurale convoluționale: Ce este învățarea automată? – Partea a 2-a”
Introducere
Aplicațiile de inteligență artificială (AI) sunt asociate, în mod tradițional, cu un consum ridicat de energie, fiind implementate frecvent în centre de date sau pe platforme hardware performante, precum matrici de porți programabile (FPGA). Provocarea actuală constă în creșterea puterii de calcul, menținând în același timp consumul energetic și costurile la un nivel redus.
În prezent, aplicațiile AI trec printr-o schimbare semnificativă, susținută de dezvoltarea calculului la marginea rețelei (Edge computing). Spre deosebire de abordările clasice bazate exclusiv pe firmware, accelerarea hardware a rețelelor neurale convoluționale (CNN) permite obținerea unor performanțe superioare de calcul, cu un raport eficiență energetică/performanță optimizat.
Prin transferarea procesării direct la nivelul nodurilor de senzori, conceptul de “Intelligent Edge” reduce semnificativ volumul de date transmis prin rețele 5G sau Wi-Fi. Această abordare deschide posibilitatea implementării unor aplicații care anterior erau dificil de realizat, precum detectoare autonome de fum sau incendiu în locații izolate ori analiza locală a datelor de mediu la nivel de senzor, cu o autonomie de funcționare de ordinul anilor alimentată de baterie.
Pentru a înțelege modul în care aceste capabilități devin realizabile, articolul analizează conversia hardware a unei rețele CNN utilizând un microcontroler dedicat pentru aplicații AI.
Microcontroler AI cu accelerator CNN integrat
Analog Devices oferă microcontrolerul MAX78000, un sistem pe cip (SoC) care integrează un accelerator hardware dedicat rețelelor neurale convoluționale (CNN), optimizat pentru consum redus de energie. Dispozitivul permite implementarea rețelelor neurale în aplicații cu resurse limitate sau în sisteme IoT de tip edge.
Aplicațiile vizate includ detectarea și clasificarea obiectelor, procesarea audio, clasificarea sunetelor, reducerea zgomotului, recunoașterea facială, analiza seriilor temporale (de exemplu, semnale de ritm cardiac sau alți indicatori de sănătate), analiza multisenzorială și întreținerea predictivă.
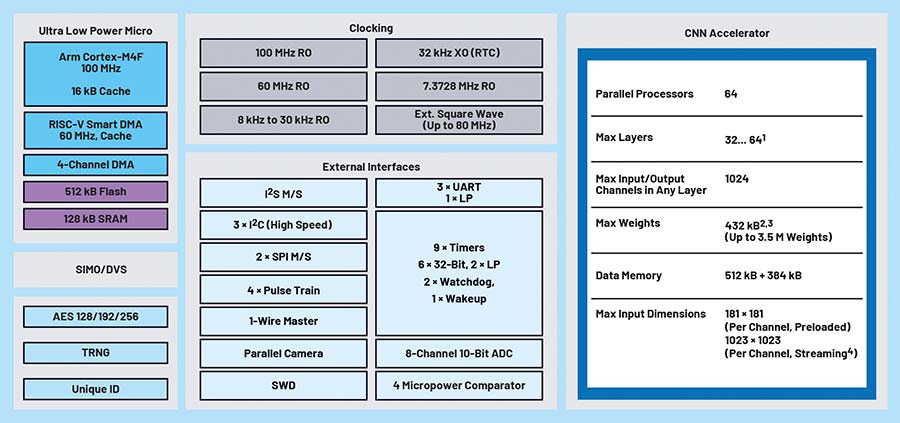
Figura 1: Diagrama bloc a dispozitivului MAX78000. (Sursă imagine: ADI)
Figura 1 prezintă diagrama bloc a microcontrolerului MAX78000, care poate funcționa la frecvențe de până la 100 MHz pe un nucleu Arm® Cortex®-M4F cu unitate în virgulă mobilă (FPU). Pentru a asigura resurse adecvate aplicațiilor, dispozitivul integrează 512 kB memorie flash și 128 kB SRAM. Sunt disponibile multiple interfețe externe, inclusiv I²C, SPI, UART și I²S, aceasta din urmă fiind relevantă pentru aplicații audio.
În plus, microcontrolerul include un nucleu RISC-V de 60 MHz, utilizat pentru gestionarea transferurilor de date între periferice și memorie (flash și SRAM), funcționând ca un motor inteligent cu acces direct la memorie (DMA). Nucleul RISC-V poate realiza preprocesarea datelor provenite de la senzori pentru acceleratorul AI, permițând nucleului Arm să intre în mod de repaus profund. Dacă este necesar, rezultatul inferenței poate genera o întrerupere pentru activarea nucleului Arm, care va executa logica principală a aplicației, va transmite datele prin interfață wireless sau va notifica utilizatorul.
Arhitectura acceleratorului CNN
O caracteristică distinctivă a seriei MAX7800x este unitatea hardware dedicată inferenței rețelelor neurale convoluționale, care diferențiază aceste microcontrolere de arhitecturile tradiționale. Acceleratorul poate susține modele CNN complete, incluzând toți parametrii necesari (ponderi și bias-uri).
Unitatea CNN integrează 64 de procesoare paralele și dispune de memorie dedicată: 442 kB pentru stocarea parametrilor și 896 kB pentru datele de intrare. Deoarece modelul și parametrii sunt stocați în memoria SRAM internă a acceleratorului, aceștia pot fi actualizați prin firmware, permițând adaptarea rețelei în timp real.
În funcție de precizia utilizată pentru ponderi (1, 2, 4 sau 8 biți), memoria disponibilă poate susține modele cu până la aproximativ 3,5 milioane de parametri. Integrarea memoriei direct în accelerator elimină necesitatea accesării repetate a magistralei principale a microcontrolerului pentru fiecare operație matematică, reducând latența și consumul de energie asociate transferurilor frecvente de date.
Acceleratorul poate susține între 32 și 64 de straturi, în funcție de utilizarea operațiilor de pooling. Dimensiunea programabilă a imaginilor de intrare și ieșire poate ajunge până la 1024 × 1024 pixeli pentru fiecare strat.
Conversia hardware CNN: comparație între consumul de energie și viteza de inferență
Inferența unei rețele neurale convoluționale (CNN) implică un volum semnificativ de operații matematice, predominant multiplicări și acumulări matriciale (MAC – Multiply-Accumulate). Utilizând capabilitățile unui nucleu Arm Cortex-M4F, inferența CNN poate fi implementată la nivel de firmware într-un sistem embedded; totuși, această abordare prezintă anumite limitări.
În cazul inferenței executate exclusiv prin firmware, consumul de energie și timpul de procesare cresc semnificativ, deoarece instrucțiunile de calcul și parametrii modelului trebuie încărcați repetat din memorie, iar rezultatele intermediare sunt scrise înapoi în memorie. Aceste transferuri frecvente de date prin magistrală contribuie atât la latență, cât și la consum energetic ridicat.
Tabelul 1 prezintă o comparație între viteza de inferență și energia consumată per inferență pentru trei scenarii distincte. Modelul utilizat pentru testare a fost antrenat pe setul de date MNIST, utilizat în mod uzual pentru recunoașterea cifrelor scrise de mână. Pentru fiecare platformă, a fost măsurat timpul necesar unei inferențe complete și energia consumată aferentă.
| Scenariu | Viteza de inferență (ms) | Energie per inferență (µWs) |
| (1) MAX32630, rețea MNIST implementată în firmware | 574 | 22887 |
| (2) MAX78000, rețea MNIST accelerată hardware | 1.42 | 20.7 |
| (3) MAX78000, rețea MNIST accelerată hardware, optimizată pentru consum redus | 0.36 | 1.1 |
Tabelul 1: Timpul și energia necesare pentru inferența CNN în trei scenarii diferite, utilizând setul de date MNIST pentru recunoașterea cifrelor scrise de mână.
Analiza comparativă a performanței și eficienței energetice
În primul scenariu, inferența a fost executată pe un procesor Arm® Cortex®-M4F integrat în microcontrolerul MAX32630, care funcționează la 96 MHz. În al doilea scenariu, calculele au fost procesate utilizând acceleratorul CNN hardware integrat în MAX78000.
Timpul de inferență – definit ca intervalul dintre aplicarea datelor de intrare la nivelul rețelei și obținerea rezultatului la ieșire – este redus de aproximativ 400 de ori atunci când se utilizează acceleratorul hardware din MAX78000. În plus, energia consumată per inferență este redusă de aproximativ 1100 de ori.
Într-un al treilea scenariu, modelul MNIST a fost optimizat pentru un consum energetic minim per inferență. În această configurație, precizia clasificării scade de la 99,6% la 95,6%. Cu toate acestea, timpul de inferență se reduce la 0,36 ms, iar energia consumată ajunge la doar 1,1 µWs per inferență.
În aplicații alimentate cu două baterii alcaline AA (energie totală aproximativ 6 Wh), pot fi realizate aproximativ cinci milioane de inferențe, fără a lua în calcul consumul energetic al celorlalte blocuri ale sistemului.
Aceste rezultate evidențiază avantajele accelerării hardware pentru aplicațiile care nu dispun de conectivitate permanentă sau de o sursă de alimentare continuă. MAX78000 permite procesarea locală la marginea rețelei, reducând necesarul energetic și eliminând dependența de lățimi de bandă ridicate sau de timpi mari de răspuns.
Exemplu de aplicație pentru microcontrolerul AI MAX78000
Microcontrolerul MAX78000 poate fi utilizat într-o varietate de aplicații, însă următorul scenariu ilustrează un caz practic relevant. Se consideră proiectarea unei camere alimentate de baterii, capabile să detecteze prezența unei pisici în câmpul vizual al senzorului de imagine și să activeze, în consecință, o ieșire digitală pentru deblocarea unei uși destinate animalelor de companie.
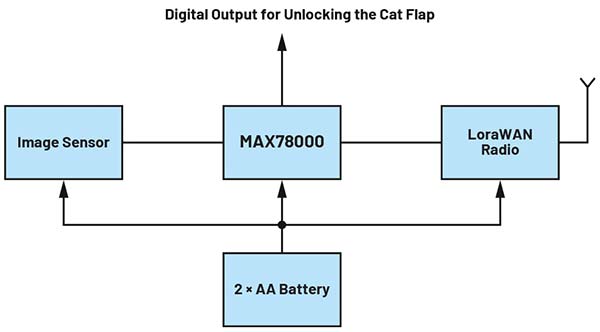
Figura 2: Diagrama bloc a unei uși inteligente pentru animale de companie. (Sursă imagine: ADI)
Figura 2 prezintă o posibilă diagramă bloc a unui astfel de sistem. În această configurație, nucleul RISC-V activează periodic senzorul de imagine, iar datele capturate sunt transmise către acceleratorul CNN integrat în MAX78000 pentru inferență. Dacă probabilitatea estimată pentru clasa “pisică” depășește un prag predefinit, ieșirea digitală comandă mecanismul ușii. Ulterior, sistemul revine în modul de consum redus (standby).
Medii de dezvoltare și kituri de evaluare
Procesul de dezvoltare a unei aplicații AI la marginea rețelei (AI-on-the-edge) poate fi împărțit în două faze principale:
Faza 1 – AI: definirea, antrenarea și cuantificarea rețelei
Faza 2 – Firmware Arm: integrarea rețelei și a parametrilor generați în faza 1 în aplicația C/C++, urmată de dezvoltarea și testarea firmware-ului
Prima etapă implică modelarea, antrenarea și evaluarea modelelor AI. Pentru această fază, dezvoltatorii pot utiliza instrumente open-source precum PyTorch și TensorFlow. Un depozit GitHub dedicat oferă resurse pentru proiectarea și antrenarea rețelelor AI utilizând mediul PyTorch, ținând cont de constrângerile hardware ale MAX78000. Acest depozit include exemple de rețele și aplicații AI simple, cum ar fi recunoașterea facială (Face ID).
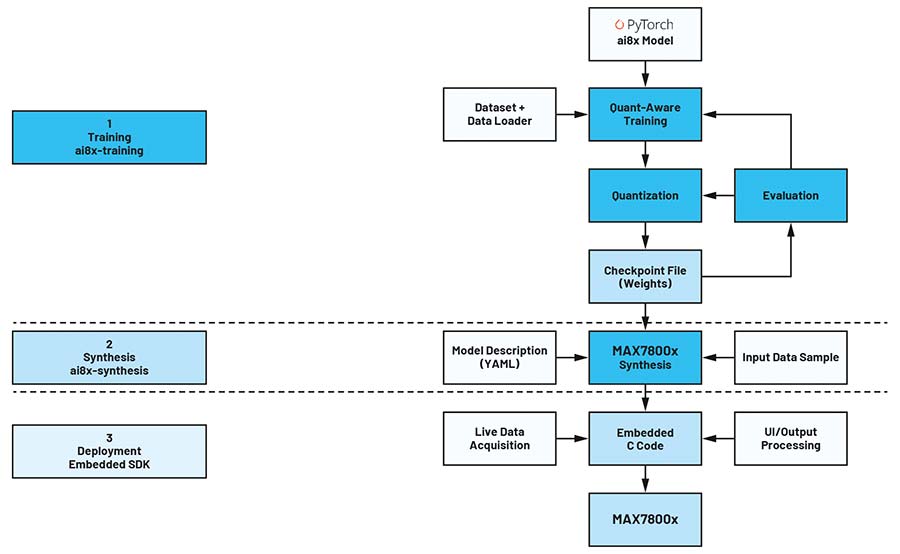
Figura 3: Proces tipic de dezvoltare AI. (Sursă imagine: ADI)
Figura 3 ilustrează fluxul tipic de dezvoltare AI în PyTorch. Inițial, rețeaua este modelată. Trebuie menționat că nu toate microcontrolerele din seria MAX7800x suportă toate operațiile disponibile în PyTorch. Din acest motiv, fișierul ai8x.py, furnizat de Analog Devices, trebuie inclus în proiect. Acesta conține modulele și operatorii PyTorch compatibili cu arhitectura MAX78000.
Pe baza acestei configurări, rețeaua este construită, antrenată, evaluată și ulterior cuantificată utilizând seturile de date corespunzătoare. Rezultatul acestei etape este un fișier de tip checkpoint, care conține parametrii necesari pentru procesul final de conversie. În etapa de sinteză, rețeaua și parametrii sunt transformați într-un format compatibil cu acceleratorul hardware CNN.
Antrenarea rețelei poate fi realizată pe un PC standard (laptop sau server). Totuși, în absența accelerării CUDA pe placă grafică dedicată, durata procesului poate crește considerabil, ajungând la zile sau chiar săptămâni pentru modele mai complexe.
Integrarea firmware și evaluarea pe hardware

Figura 4: Kit de evaluare pentru MAX78000. (Sursă imagine: ADI)
În faza a doua, este dezvoltat firmware-ul aplicației, incluzând mecanismele de încărcare a parametrilor în acceleratorul CNN și citirea rezultatelor inferenței. Fișierele generate în prima etapă sunt integrate în proiectul C/C++ prin directive #include.
Pentru dezvoltarea firmware-ului pot fi utilizate instrumente open-source precum Eclipse IDE și GNU Toolchain. ADI oferă, de asemenea, pachetul Maxim Micros SDK (Windows) disponibil sub formă de instalator, care include toate componentele și configurațiile necesare pentru dezvoltare. Kitul software conține drivere pentru periferice, exemple de proiecte și documentație menită să simplifice procesul de implementare.

Figura 5: Kit de evaluare pentru MAX78000FTHR. (Sursă imagine: ADI)
După compilarea și conectarea proiectului fără erori, aplicația poate fi evaluată pe hardware-ul țintă. ADI pune la dispoziție două platforme de evaluare dedicate. Figura 4 prezintă kitul MAX78000EVKIT, iar Figura 5 prezintă kitul MAX78000FTHR, o placă compactă, compatibilă cu standardul Adafruit Feather. Ambele platforme sunt echipate cu o cameră VGA și un microfon, facilitând testarea aplicațiilor de procesare imagine și audio.
Concluzie
În mod tradițional, aplicațiile de inteligență artificială au fost asociate cu un consum energetic ridicat, fiind implementate în centre de date sau pe platforme hardware performante, precum FPGA-uri dedicate. Integrarea unui accelerator CNN hardware în familia de microcontrolere MAX78000 permite însă realizarea inferenței direct la marginea rețelei, cu un consum energetic semnificativ redus.
Această arhitectură face posibilă implementarea aplicațiilor AI alimentate de la baterie, pentru perioade extinse de funcționare, fără a depinde de infrastructură de calcul externă sau de conectivitate permanentă. Prin combinarea unui nucleu Arm, a unui nucleu RISC-V și a unui accelerator CNN dedicat, MAX78000 oferă o soluție eficientă pentru procesarea locală a modelelor neurale.
Pentru informații suplimentare despre microcontrolerele optimizate pentru aplicații AI cu consum redus de energie, consultați documentația dedicată familiei MAX78000.
Referințe
“Session 2 – AI at the Edge: A Practical Introduction to Maxim Integrated’s MAX78000 AI Accelerator.” Analog Devices, Inc.
Video Series: Understanding Artificial Intelligence. Analog Devices, Inc.
The PyTorch logo is used with permission under the Creative Commons Attribution-Share Alike 4.0 International license.
Autor: Ole Dreessen, Field Applications Staff Engineer, Analog Devices
Vizitați https://ez.analog.com
![]()
Glosar de termeni
CNN (Convolutional Neural Network) – Rețea neurală convoluțională utilizată în principal pentru recunoașterea imaginilor, clasificarea obiectelor și analiza datelor vizuale sau audio.
Inferență – Procesul prin care un model AI antrenat generează un rezultat (predicție sau clasificare) pe baza unor date de intrare.
Cuantificare (Quantization) – Reducerea preciziei numerice a ponderilor și activărilor unui model (de exemplu, la 8, 4, 2 sau 1 bit) pentru a diminua consumul de memorie și energie.
Accelerator CNN hardware – Unitate dedicată integrată în microcontroler pentru executarea eficientă a operațiilor specifice rețelelor neurale, reducând consumul și latența.
MAC (Multiply-Accumulate) – Operație matematică fundamentală în rețelele neurale, constând în înmulțire urmată de acumulare.
Edge computing (calcul la marginea rețelei) – Procesarea datelor direct la nivelul dispozitivului sau senzorului, fără trimiterea acestora către cloud.
Intelligent Edge – Concept ce descrie dispozitive capabile să execute inferență AI local, cu autonomie energetică ridicată.
Checkpoint – Fișier generat în timpul antrenării unei rețele neurale, conținând parametrii modelului salvați pentru utilizare ulterioară.
CUDA – Platformă de calcul paralel utilizată pentru accelerarea antrenării modelelor AI pe GPU-uri NVIDIA.