


Introducere în rețelele neurale convoluționale: Ce este învățarea automată?
Lumea inteligenței artificiale (AI) evoluează rapid, iar AI permite tot mai multe aplicații care, până de curând, erau imposibil de realizat sau foarte dificil de implementat. Această serie de articole explică rețelele neurale convoluționale (CNN) și importanța lor în învățarea automată în cadrul sistemelor AI. CNN-urile sunt instrumente puternice pentru extragerea caracteristicilor din date complexe, precum recunoașterea modelelor sofisticate în semnale audio sau în imagini.
Acest articol analizează avantajele CNN-urilor în comparație cu programarea liniară clasică. Un articol ulterior, “Antrenarea rețelelor neurale convoluționale” – Partea a 2-a, va analiza modul în care sunt antrenate modelele CNN. Partea a 3-a va examina un caz de utilizare specific, în care modelul este testat folosind un microcontroler AI dedicat.
Ce sunt rețelele neurale convoluționale?
Rețelele neurale sunt structuri inspirate de neuronii biologici, care permit sistemelor AI să înțeleagă și să interpreteze mai bine datele, ajutându-le să rezolve probleme complexe. Deși există numeroase tipuri de rețele neurale, această serie de articole se concentrează exclusiv pe rețelele neurale convoluționale (CNN).
Principalele domenii de aplicare ale CNN-urilor sunt recunoașterea modelelor și clasificarea obiectelor conținute în datele de intrare. CNN-urile reprezintă un tip de rețea neurală artificială utilizată în învățarea profundă (deep learning). Aceste rețele sunt alcătuite dintr-un strat de intrare, mai multe straturi convoluționale și un strat de ieșire.
Straturile convoluționale sunt componentele esențiale, deoarece utilizează seturi de ponderi și filtre care permit rețelei să extragă caracteristici relevante din datele de intrare. Datele pot avea forme variate, precum imagini, semnale audio sau text. Acest proces de extragere a caracteristicilor permite CNN-urilor să identifice tipare și structuri în date.
Prin această abordare, CNN-urile le permit inginerilor să dezvolte aplicații mai eficiente și mai performante. Pentru a înțelege mai bine modul în care funcționează CNN-urile, vom discuta mai întâi despre principiile programării liniare clasice.
Executarea programului liniar în ingineria de control clasică
În ingineria de control, sarcina principală constă în citirea datelor de la unul sau mai mulți senzori, procesarea acestora, reacția conform unor reguli prestabilite și afișarea sau transmiterea rezultatelor. De exemplu, un regulator de temperatură măsoară temperatura la intervale regulate cu ajutorul unui microcontroler (MCU), care citește datele furnizate de senzorul de temperatură. Valorile obținute sunt utilizate ca date de intrare într-un sistem de control în buclă închisă și sunt comparate cu valoarea de referință setată.
Acesta este un exemplu de execuție liniară, realizată de microcontroler. Această tehnică oferă rezultate deterministe, bazate pe un set de valori preprogramate și pe date reale de intrare. În schimb, în funcționarea sistemelor de inteligență artificială, probabilitățile joacă un rol esențial.
Procesarea complexă a modelelor și a semnalelor
Există numeroase aplicații care utilizează date de intrare ce trebuie mai întâi interpretate de un sistem de recunoaștere a modelelor. Recunoașterea modelelor poate fi aplicată unor structuri de date variate. În exemplele prezentate aici, ne limităm la structuri de date unidimensionale și bidimensionale. Exemplele includ semnale audio, electrocardiograme (ECG), fotopletismograme (PPG) și vibrații pentru date unidimensionale, precum și imagini, imagini termice sau diagrame în cascadă pentru date bidimensionale.
În cazurile de recunoaștere a modelelor menționate, conversia aplicației într-un cod clasic pentru microcontroler este extrem de dificilă. Un exemplu relevant este recunoașterea unui obiect (de exemplu, o pisică) într-o imagine. În acest context, nu contează dacă imaginea analizată provine dintr-o înregistrare anterioară sau este capturată în timp real de senzorul camerei. Software-ul de analiză efectuează o căutare bazată pe reguli pentru a identifica modele asociate unei pisici, precum urechile ascuțite, nasul triunghiular sau mustățile.
Dacă aceste caracteristici sunt recunoscute în imagine, software-ul raportează detectarea unei pisici. Însă apar rapid întrebări suplimentare: ce s-ar întâmpla dacă pisica ar fi surprinsă doar din spate? Sau dacă nu ar avea mustăți ori ar lipsi unele membre în urma unui accident? Deși astfel de cazuri sunt puțin probabile, codul de recunoaștere a modelelor ar trebui să includă un număr foarte mare de reguli suplimentare pentru a acoperi toate aceste situații.
Chiar și în acest exemplu simplificat, regulile definite de software ar deveni rapid extrem de complexe.
Cum înlocuiește învățarea automată regulile clasice
Ideea din spatele inteligenței artificiale este de a imita, la scară redusă, modul în care învață oamenii. În loc să formulăm un număr mare de reguli de tip “dacă–atunci”, construim un sistem general de recunoaștere a modelelor. Diferența esențială dintre cele două abordări este că AI, spre deosebire de un set rigid de reguli, nu furnizează un rezultat determinist.
În loc să raporteze “Am recunoscut o pisică în imagine”, un sistem de învățare automată produce un rezultat de forma: “Există o probabilitate de 97,5% ca în imagine să fie o pisică. Ar putea fi și un leopard (2,1%) sau un tigru (0,4%)”. Acest lucru înseamnă că dezvoltatorul unei astfel de aplicații trebuie să ia o decizie la finalul procesului de recunoaștere a modelelor. În practică, acest lucru se realizează prin definirea unui prag de decizie.
O altă diferență majoră este faptul că un sistem de recunoaștere a modelelor nu este echipat cu reguli fixe. În schimb, acesta este antrenat. În cadrul acestui proces de învățare, unei rețele neurale îi este prezentat un număr mare de imagini cu pisici. În final, rețeaua devine capabilă să determine singură dacă într-o imagine apare sau nu o pisică.
Aspectul esențial este că recunoașterea ulterioară nu se limitează la imaginile utilizate în procesul de antrenare. Modelul învățat trebuie apoi implementat pe un microcontroler sau pe un alt sistem embedded, pentru a putea fi utilizat în aplicații reale.
Cum arată exact un sistem de recunoaștere a modelelor în interior?
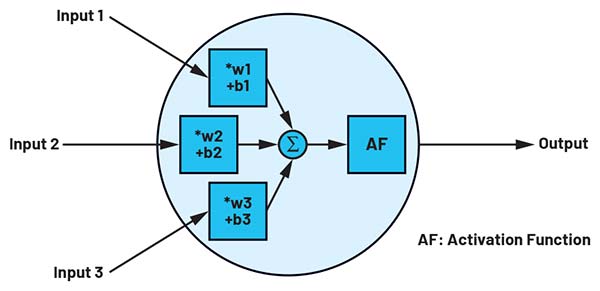
Figura 1: Un neuron cu trei intrări și o ieșire. (Sursa imaginii: ADI)
Cum funcționează un neuron artificial
O rețea de neuroni utilizată în inteligența artificială seamănă, la nivel conceptual, cu cea biologică din creierul uman. Un neuron are mai multe intrări și o singură ieșire. Din punct de vedere matematic, un astfel de neuron reprezintă o transformare liniară a intrărilor – înmulțirea acestora cu valori numerice numite ponderi (weights, w) și adăugarea unei constante numite bias (b) – urmată de aplicarea unei funcții neliniare fixe, cunoscută sub denumirea de funcție de activare.1 Funcția de activare, care reprezintă singura componentă neliniară a rețelei, are rolul de a defini intervalul de valori în care un neuron artificial se activează. Funcția unui neuron poate fi descrisă matematic ca:
![]()
unde f este funcția de activare, w reprezintă ponderea (weight), x sunt datele de intrare, iar b este termenul de bias. Datele de intrare pot fi scalari individuali, vectori sau matrice. Figura 1 ilustrează un neuron cu trei intrări și o funcție de activare ReLU2. Neuronii dintr-o rețea sunt organizați întotdeauna în straturi.
Structura unei rețele neurale convoluționale
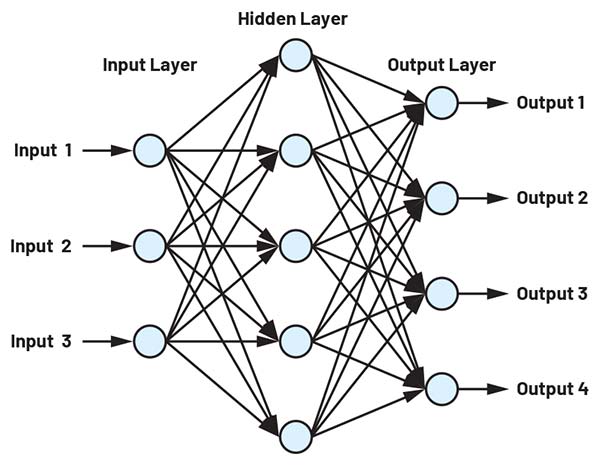
Figura 2: O rețea neurală de dimensiuni reduse. (Sursa imaginii: ADI)
După cum s-a menționat anterior, rețelele neurale convoluționale (CNN) sunt utilizate pentru recunoașterea tiparelor și clasificarea obiectelor conținute în datele de intrare. O CNN este structurată în mai multe secțiuni: un strat de intrare, unul sau mai multe straturi ascunse și un strat de ieșire. O rețea simplă, cu trei intrări, un strat ascuns format din cinci neuroni și un strat de ieșire cu patru ieșiri, este ilustrată în Figura 2.
În această structură, ieșirile tuturor neuronilor dintr-un strat sunt conectate la toate intrările neuronilor din stratul următor. Rețeaua prezentată în Figura 2 nu este capabilă să rezolve sarcini complexe și este utilizată aici exclusiv în scop demonstrativ. Chiar și în cazul acestei rețele simple, ecuația care descrie funcționarea sa include 32 de termeni de bias și 32 de ponderi.
Convoluția și extragerea caracteristicilor din imagini
O rețea neurală CIFAR este un tip de rețea neurală convoluțională (CNN) utilizată pe scară largă în sarcini de recunoaștere a imaginilor. Aceasta este alcătuită din două tipuri principale de straturi: straturi convoluționale și straturi de pooling, ambele având un rol esențial în antrenarea rețelelor neurale.
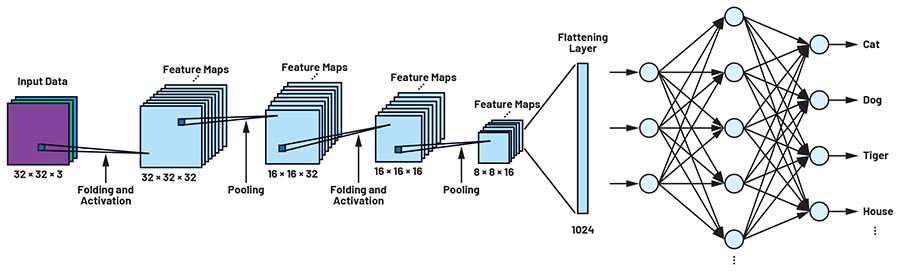
Figura 3: Model al unei rețele CIFAR antrenate pe setul de date CIFAR-10. (Sursa imaginii: ADI)
Stratul convoluțional utilizează o operație matematică numită convoluție pentru a identifica tipare într-o matrice de valori de pixeli. Convoluția are loc în straturile ascunse, așa cum este ilustrat în Figura 3. Acest proces se repetă de mai multe ori, până când se atinge nivelul dorit de precizie.
Este important de menționat că valoarea de ieșire a unei operații de convoluție este ridicată atunci când cele două intrări comparate – în acest caz imaginea și filtrul – sunt similare. Acest filtru este reprezentat sub forma unei matrice de filtrare, cunoscută și sub denumirea de kernel de filtrare sau, simplu, filtru.
Rezultatele sunt apoi transmise către stratul de pooling, care generează o hartă de caracteristici (feature map) – o reprezentare a datelor de intrare ce evidențiază caracteristicile relevante. Această hartă poate fi privită ca o altă matrice derivată din procesul de filtrare.
După finalizarea antrenării, în faza operațională a rețelei, aceste hărți de caracteristici sunt comparate cu datele de intrare. Deoarece hărțile de caracteristici conțin informații specifice claselor de obiecte, neuronii din rețea se activează doar atunci când conținutul imaginilor de intrare este suficient de similar cu aceste caracteristici învățate.
Prin combinarea straturilor convoluționale și de pooling, rețeaua CIFAR poate fi utilizată pentru recunoașterea și clasificarea diverselor obiecte dintr-o imagine, cu un nivel ridicat de acuratețe.
1 Se utilizează frecvent funcții de activare precum sigmoid, tanh sau ReLU.
2 ReLU (Rectified Linear Unit): funcție de activare în care valorile de intrare negative sunt mapate la zero, iar valorile pozitive sunt transmise neschimbate.
Rolul setului de date CIFAR-10 în antrenarea CNN-urilor
CIFAR-10 este un set de date utilizat pe scară largă pentru antrenarea rețelelor neurale convoluționale de tip CIFAR. Acesta este alcătuit din 60.000 de imagini color cu rezoluția de 32 × 32 de pixeli, împărțite în 10 clase. Imaginile au fost colectate din surse diverse, precum pagini web, grupuri de știri și colecții personale. Fiecare clasă conține 6000 de imagini, împărțite între seturile de antrenare, testare și validare, ceea ce face din CIFAR-10 un set de date ideal pentru evaluarea noilor arhitecturi de viziune computerizată și a altor modele de învățare automată.
Procesarea progresivă a caracteristicilor în rețelele CNN
Principala diferență dintre rețelele neurale convoluționale și alte tipuri de rețele constă în modul de procesare a datelor. Prin intermediul filtrării, datele de intrare sunt analizate progresiv pentru a li se identifica proprietățile. Pe măsură ce numărul de straturi convoluționale conectate în serie crește, crește și nivelul de detaliu care poate fi recunoscut.
Procesul începe cu identificarea unor caracteristici simple ale obiectelor, cum ar fi marginile sau punctele, după prima convoluție, și continuă cu structuri mai complexe, precum colțuri, cercuri sau dreptunghiuri, după a doua convoluție. După a treia convoluție, caracteristicile extrase corespund unor modele complexe, asemănătoare părților componente ale obiectelor din imagini, care sunt, de regulă, specifice unei anumite clase. În exemplul nostru inițial, acestea pot fi mustățile sau urechile unei pisici. Vizualizarea hărților de caracteristici – ilustrată în Figura 4 – nu este necesară pentru funcționarea aplicației propriu-zise, dar este utilă pentru înțelegerea mecanismului de convoluție.
Complexitatea rețelelor și rolul straturilor de pooling
Chiar și rețelele de dimensiuni reduse, precum CIFAR, includ sute de neuroni în fiecare strat și numeroase straturi conectate în serie. Numărul de ponderi și biasuri crește rapid odată cu sporirea complexității și dimensiunii rețelei. În exemplul CIFAR-10 ilustrat în Figura 3, există deja aproximativ 200.000 de parametri care trebuie determinați în timpul procesului de antrenare. Hărțile de caracteristici pot fi procesate în continuare prin straturi de pooling, care reduc numărul de parametri necesari antrenării, păstrând în același timp informațiile esențiale.
Pooling, aplatizare și clasificare finală

Figura 4: Hărți de caracteristici pentru o rețea CNN. (Sursa imaginii: ADI)
Așa cum s-a menționat, după fiecare operație de convoluție într-o rețea CNN este utilizat frecvent un strat de pooling, denumit și subsampling în literatura de specialitate. Rolul acestuia este de a reduce dimensiunea datelor. Dacă analizăm hărțile de caracteristici din Figura 4, se poate observa că regiunile extinse conțin foarte puține informații relevante sau chiar deloc. Acest lucru se datorează faptului că obiectele de interes nu ocupă întreaga imagine, ci doar o mică parte a acesteia. Restul imaginii nu este utilizat în harta de caracteristici respectivă și, prin urmare, nu contribuie la procesul de clasificare.
Tipuri de pooling și reducerea volumului de date
Într-un strat de pooling sunt definiți atât tipul de pooling (maxim sau mediu), cât și dimensiunea ferestrei de procesare. Fereastra este deplasată incremental peste datele de intrare pe parcursul procesului de pooling. În cazul pooling-ului maxim (max pooling), este selectată cea mai mare valoare din fiecare fereastră, iar celelalte valori sunt eliminate. Astfel, volumul de date este redus progresiv și, împreună cu straturile convoluționale, sunt extrase caracteristicile distinctive ale clasei de obiecte analizate.
De la hărți bidimensionale la decizia de clasificare
Rezultatul acestor etape succesive de convoluție și pooling constă într-un număr mare de matrici bidimensionale. Pentru a atinge obiectivul final de clasificare, aceste date bidimensionale sunt transformate într-un vector unidimensional de mari dimensiuni. Conversia este realizată într-un așa-numit strat de aplatizare (flattening layer), urmat de unul sau mai multe straturi complet conectate (fully connected layers). Neuronii din aceste straturi au o structură similară celei ilustrate în Figura 2.
Ultimul strat al rețelei neurale conține exact atâtea ieșiri câte clase trebuie diferențiate. În acest strat, valorile sunt normalizate pentru a genera o distribuție de probabilitate, de exemplu: 97,5% pisică, 2,1% leopard, 0,4% tigru etc.
Astfel se încheie etapa de modelare a rețelei neurale. Totuși, ponderile și valorile matricelor de kernel și filtrare nu sunt încă cunoscute și trebuie determinate prin procesul de antrenare a rețelei pentru ca modelul să funcționeze corect. Acest proces va fi prezentat în articolul următor, “Antrenarea rețelelor neurale convoluționale – Partea a 2-a”. Partea a 3-a va aborda implementarea hardware a rețelei neurale discutate, utilizând ca exemplu recunoașterea imaginilor cu pisici, pe baza microcontrolerului AI MAX78000, echipat cu accelerator CNN hardware dezvoltat de Analog Devices.
Autor: Ole Dreessen, Staff Engineer, Field Applications
Despre autor: Ole Dreessen este inginer de aplicații de teren la Analog Devices. Înainte de a se alătura companiei ADI în 2014, a ocupat diverse poziții la Avnet Memec și Macnica, unde a oferit suport tehnic pentru tehnologii de comunicații și microprocesoare de înaltă performanță. Ole are o experiență vastă în domeniul microcontrolerelor și al securității și este un prezentator experimentat în cadrul conferințelor și evenimentelor dedicate distribuției. În timpul liber, este membru activ al Chaos Computer Club, unde a lucrat la concepte precum ingineria inversă și securitatea sistemelor embedded.
Vizitați https://ez.analog.com
![]()
Glosar de termeni
- Rețea neurală artificială: Model matematic inspirat de structura creierului uman, alcătuit din neuroni artificiali organizați în straturi, utilizat pentru recunoașterea tiparelor și clasificare.
- Rețea neurală convoluțională (CNN): Tip de rețea neurală utilizată în principal pentru procesarea imaginilor și a semnalelor, bazată pe operații de convoluție și pooling pentru extragerea caracteristicilor relevante.
- Convoluție: Operație matematică prin care un filtru (kernel) este aplicat peste datele de intrare pentru a detecta caracteristici precum margini, colțuri sau texturi.
- Kernel (filtru): Matrice de dimensiuni reduse utilizată în operația de convoluție pentru a extrage caracteristici specifice din datele de intrare.
- Pooling (subsampling): Proces de reducere a dimensiunii datelor prin selectarea valorilor maxime sau medii din regiuni locale, păstrând informația relevantă și reducând complexitatea calculului.
- Strat de aplatizare (Flatten layer): Strat care transformă datele bidimensionale rezultate din convoluții într-un vector unidimensional, pregătit pentru clasificare.
- Strat complet conectat (Fully Connected Layer): Strat al unei rețele neurale în care fiecare neuron este conectat la toți neuronii din stratul precedent, utilizat pentru luarea deciziei finale.
- Funcție de activare ReLU: Funcție neliniară utilizată frecvent în CNN-uri, care elimină valorile negative și păstrează valorile pozitive, accelerând procesul de antrenare.
- CIFAR-10: Set de date standard utilizat pentru antrenarea și evaluarea rețelelor neurale convoluționale, conținând 60.000 de imagini color împărțite în 10 clase.
- Antrenarea rețelei: Proces prin care ponderile și biasurile unei rețele neurale sunt ajustate pe baza datelor de antrenament pentru a minimiza eroarea de clasificare.
- Microcontroler AI: Microcontroler care integrează acceleratoare hardware dedicate pentru inferență AI, permițând rularea eficientă a modelelor de învățare automată la nivel embedded.