

Implementați AI la nivel de dispozitiv cu ajutorul opțiunilor de optimizare TinyML
Inteligența artificială (AI) oferă producătorilor de dispozitive și electrocasnice o gamă largă de posibilități. Producătorii și furnizorii de servicii apelează la AI pentru a îmbunătăți performanța produselor și pentru a crește gradul de satisfacție al utilizatorilor.
Caracterul acestei tehnologii permite aplicarea sa în situații în care programarea prin algoritmi “clasici” sau “tradiționali” este dificilă sau ineficientă. Am observat deja modul în care AI transformă experiența utilizatorului în dispozitivele controlate vocal – însă aplicațiile merg mult mai departe.
Cu ajutorul inteligenței artificiale, dispozitivele își pot monitoriza propriul comportament. De exemplu, mașinile de spălat își pot supraveghea motoarele și pot utiliza senzorii încorporați pentru a determina momentul optim pentru rularea programelor de curățare a tamburului. Alte aplicații AI pot îmbunătăți securitatea și fiabilitatea: senzorii inteligenți utilizați în medii industriale pot detecta comportamente anormale și pot alerta restul rețelei atunci când există indicii de defect hardware sau de utilizare necorespunzătoare.
Primul val de sisteme embedded care au integrat AI s-a bazat pe procesarea în cloud. Aceasta a permis utilizarea unor modele mai mari, care altfel ar consuma prea multă energie sau ar fi prea lente pentru a rula pe microcontrolerele folosite în majoritatea sistemelor embedded. Totuși, soluțiile AI bazate pe cloud ridică mai multe provocări pentru producătorii de electrocasnice și, în același timp, generează îngrijorări din partea utilizatorilor finali – din diverse motive.
Compromisuri energetice
Deși transferul procesării AI către cloud eliberează sistemul embedded de sarcina rulării calculelor modelului, acesta crește consumul de energie al subsistemului de comunicații. În comunicațiile wireless, transmisia consumă semnificativ mai multă energie decât recepția datelor pe aceeași legătură. Dispozitivul poate fi nevoit să trimită volume mari de date audio sau de imagine către cloud printr-o rețea fără fir. Cum răspunsurile sunt adesea scurte și simple, această abordare nu corespunde constrângerilor de alimentare ale unui dispozitiv tipic alimentat cu baterii.
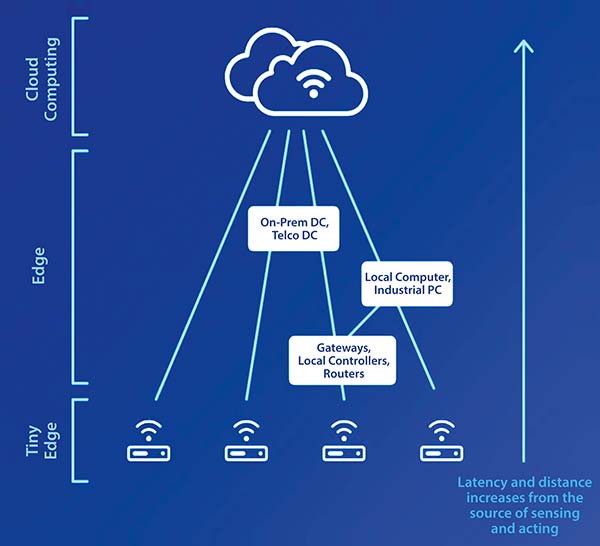
Figura 1: Latența este un factor important în decizia de a transfera procesarea AI către sisteme de calcul îndepărtate și depinde în mare măsură de distanța până la cel mai apropiat serviciu disponibil. (Sursa: Silicon Labs)
Latența reprezintă o altă problemă practică. Întârzierea totală dus-întors pentru fiecare solicitare trimisă către cloud depășește adesea 100 ms – uneori mult mai mult, dacă centrul de date relevant se află pe un alt continent. Pentru o interfață cu utilizatorul bazată pe AI, o astfel de întârziere poate fi inacceptabilă. De exemplu, un model conceput pentru a gestiona comenzi vocale scurte impune un răspuns aproape instantaneu. Latența poate fi redusă dacă transferul de sarcină (offloading) se realizează către servere periferice (edge servers) situate în aceeași regiune. Totuși, asigurarea accesului constant la această putere de procesare devine mai dificilă pe măsură ce baza de utilizatori crește.
Modele bazate pe cloud
Modelele bazate pe cloud ridică probleme legate de confidențialitate. Consumatorii nu se simt confortabil cu ideea că dispozitivele lor pot înregistra conversațiile complete și le pot trimite în cloud pentru transcriere, doar pentru a identifica expresiile folosite ca fraze de comandă. În mod similar, utilizatorii industriali nu doresc ca datele detaliate provenite de la senzori să fie transmise și stocate în cloud pentru ca un model AI să efectueze analize de întreținere predictivă. Datele senzorilor pot conține informații sensibile despre procesele interne, care ar putea fi de mare interes pentru concurenți, dacă ar ajunge în posesia acestora.
Pentru producătorii de electrocasnice, transferul responsabilităților AI către dispozitiv le permite să ofere servicii sustenabile pe termen lung. O problemă majoră asociată utilizării cloudului pentru procesarea AI este creșterea rapidă a costurilor legate de utilizarea infrastructurilor partajate de calcul. Variabilitatea acestor costuri îngreunează stabilirea prețului final al produselor, în special atunci când un model bazat pe abonament sau servicii nu este fezabil pentru piața țintă.
În anumite cazuri, asigurarea unei conectivități suficient de fiabile pentru utilizare continuă este pur și simplu imposibilă. De exemplu, în cazul dispozitivelor inteligente atașate animalelor, acestea se pot afla ocazional în raza de acțiune a unui router wireless, însă lățimea de bandă a rețelei nu este suficientă pentru a menține o conexiune fiabilă. În aceste situații, este mai eficient ca procesarea să se efectueze local, folosind legătura wireless doar pentru transmiterea rezultatelor sau a metadatelor.
Optimizări AI pentru sistemele embedded
Deși, în trecut, producătorii OEM apelau la procesarea bazată pe cloud pentru modelele AI, din cauza costurilor ridicate de calcul, astăzi există numeroase modalități de optimizare a tehnologiei pentru execuția directă pe microcontrolere. Cheia constă în înțelegerea modului de a valorifica la maximum învățarea automată și AI pentru fiecare aplicație specifică. Un exemplu de aplicație care, cu o planificare atentă, poate rula independent pe un dispozitiv embedded este detectarea cuvintelor cheie sau a cuvintelor de activare (wakewords) și recunoașterea comenzilor vocale simple.
Într-un astfel de caz, timpul și energia necesare pentru recunoașterea faptului că utilizatorul a rostit un cuvânt de activare sau de control trebuie reduse la minimum. Aceasta evidențiază avantajele utilizării AI direct pe dispozitiv, eliminând necesitatea transmiterii continue a datelor audio către cloud și permițând activarea restului sistemului pentru transmiterea în flux doar atunci când este necesar.
Oportunități imediate de economisire a energiei
Există oportunități imediate de economisire a energiei în această abordare a sistemului permanent activ. Una dintre acestea constă în activarea modelului de recunoaștere a cuvintelor numai atunci când este detectat un semnal care se conformează modelelor tipice de vorbire. Nu este necesară menținerea subsistemului în funcțiune dacă singurul semnal primit este zgomotul de fond – aceasta este așa-numita detectare a activității vocale (VAD – Voice Activity Detection). Filtrarea poate ajuta la identificarea și izolarea frecvențelor vocale relevante din zgomotul de bandă largă. În multe aplicații AI, este logic să se efectueze o preprocesare a semnalului vocal digitalizat.
De exemplu, poate fi mai ușor pentru modele să recunoască formele cuvintelor prin antrenarea pe reprezentări timp-frecvență, cum ar fi spectrogramele semnalului audio, decât pe eșantioane brute în domeniul timpului. Spectrogramele pot necesita semnificativ mai puțină memorie decât fluxurile complete de eșantioane. De exemplu, un bloc de eșantioane pe 16 biți poate fi redus cu ușurință la componente de 8 biți în formă spectrală. Aceasta nu afectează neapărat precizia modelului antrenat, dar reduce atât costurile de antrenare, cât și pe cele de inferență, aducând beneficii suplimentare în ceea ce privește spațiul de stocare necesar pentru datele audio analizate.
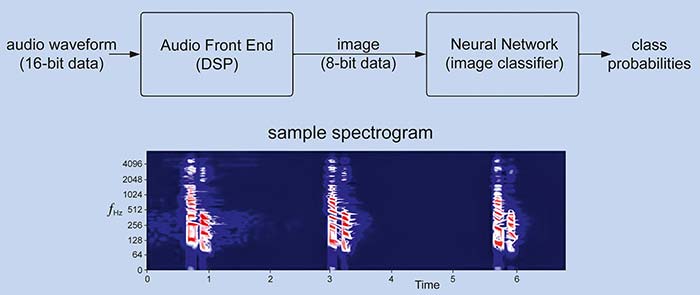
Figura 2: Conversia eșantioanelor de vorbire într-o reprezentare spectrală poate reduce amprenta totală de memorie a aplicației și poate facilita procesarea semnalelor vocale. (Sursa: Silicon Labs)
O preprocesare suplimentară poate simplifica activitatea modelului AI utilizat pentru clasificarea enunțurilor în comenzi recunoscute și alte tipuri de vorbire. O problemă esențială în acest tip de aplicație este modul optim de furnizare a enunțurilor către clasificator. Dacă un algoritm de preprocesare împarte fluxul vocal în segmente de dimensiuni egale, este posibil ca unele enunțuri să fie trunchiate – adică să conțină doar părți din cuvinte sau silabe incomplete. Astfel, informații importante pot fi împărțite între mai multe segmente.
Preprocesare suplimentară
Aplicarea unei preprocesări suplimentare, care încearcă să separe fluxul vocal în cuvinte sau silabe complete, poate îmbunătăți precizia și reduce erorile. În plus, acest lucru poate conduce la un model mai mic și mai eficient.
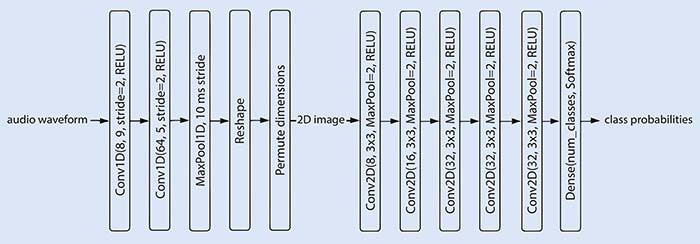
Figura 3: Un exemplu de flux de procesare a vorbirii care utilizează modele AI de la un capăt la altul. (Sursa: Silicon Labs)
Există adesea compromisuri interesante între utilizarea procesării convenționale a semnalului în etapa de preprocesare și aplicarea unui al doilea model AI. O strategie clasică de procesare a semnalului constă în analizarea variațiilor energiei semnalului audio și în segmentarea acestuia în funcție de intervalele în care energia este minimă. Această tehnică permite izolarea cuvintelor sau a silabelor individuale.
Experimentarea este esențială
Este posibil nu doar să înlocuiți blocul DSP de preprocesare cu o rețea neurală convoluțională unidimensională (1D CNN), ci și să îmbunătățiți eficiența generală a procesării. O proiectare atentă a acestui model 1D permite rularea CNN-ului la o rată efectivă de 16 ksample/s, suficientă pentru procesarea semnalului vocal. Modelul dezvoltat în cadrul proiectului a utilizat aproximativ 28.000 de parametri neurali, oferind o abordare extrem de eficientă din punctul de vedere al utilizării memoriei.
Optimizarea suplimentară a clasificatorului reduce și mai mult numărul de calcule necesare pentru inferență. Echipa a descoperit că utilizarea convoluției separabile în profunzime (depthwise separable convolution), în care fluxul de date este împărțit în canale cu rezoluție mai mică, a permis reducerea numărului total de parametri. Aceasta, la rândul ei, a redus numărul total de operații de calcul cu un factor de 10.
O optimizare suplimentară derivă din utilizarea tehnicilor de procesare în serie (pipelining), care elimină necesitatea recalculării întregii rețele neurale convoluționale pe măsură ce noi eșantioane audio sunt introduse în rețea.
Pipelining
Pipelining-ul contribuie la reducerea cantității de memorie de lucru necesare, deoarece permite straturilor individuale din cadrul modelului de clasificare să proceseze secvențial intrări parțiale, în loc să aștepte finalizarea procesării unui cadru complet de către stratul precedent – cadru care ar trebui altfel stocat în memoria de lucru.
O atenție similară la detalii poate valorifica pe deplin potențialul AI-ului integrat în dispozitiv într-o gamă largă de aplicații, unele dintre acestea oferind modalități inovatoare de utilizare a senzorilor existenți.
Într-un alt proiect, Silicon Labs explorează utilizarea AI-ului integrat în dispozitiv pentru implementarea unor forme mai avansate de detectare a corpului și a mișcării în camere, prin analiza informațiilor de dispersie provenite de la transceivere wireless, precum cele integrate în SoC-ul EFR32BG24.
Cercetările au examinat modul în care utilizarea altor modele clasice de învățare automată, cum ar fi pădurile aleatorii (random forests), ar putea oferi rezultate precise cu un cost redus de calcul și de memorie, comparativ cu rețelele neurale convoluționale (CNN).
Nota redacției:
Termenul “păduri aleatorii” (random forests) se referă la o metodă de învățare automată bazată pe un ansamblu de arbori de decizie. Fiecare arbore analizează datele independent, iar rezultatul final este obținut prin “votul” majoritar al arborilor. Acest tip de model oferă o precizie bună cu un consum redus de resurse, fiind potrivit pentru aplicațiile embedded și TinyML.
Fundația TinyML
Dezvoltatorii nu sunt singuri în această nouă etapă a evoluției sistemelor embedded. Silicon Labs este un membru activ al Fundației TinyML, o comunitate globală dedicată creșterii eficienței AI-ului integrat în dispozitive. Fundația urmărește să încurajeze adoptarea pe scară largă a aplicațiilor TinyML în sistemele embedded și împărtășește în mod activ cunoștințe și resurse pentru a sprijini formarea și educarea utilizatorilor.
Activitatea Fundației TinyML, împreună cu cea a Silicon Labs, ajută dezvoltatorii să descopere noi aplicații și provocări pe care tehnicile de învățare automată embedded le pot aborda cu succes. Acest tip de implicare este esențial pentru a accelera adoptarea AI-ului la nivel de dispozitiv, într-un moment în care tot mai mulți producători caută să reducă dependența de cloud. Silicon Labs este acolo pentru a sprijini această tranziție.
Autori:
Tamas Daranyi, Product Manager, Silicon Labs
Javier Elenes, Distinguished Engineer, Silicon Labs
Glosar de termeni
- TinyML – Ramură a inteligenței artificiale (AI) care se concentrează pe rularea modelelor de învățare automată direct pe microcontrolere și dispozitive embedded cu resurse limitate (memorie, putere de calcul, consum energetic).
- Pipelining – Tehnică de procesare în serie care permite execuția simultană a mai multor etape ale unui algoritm, reducând timpul total de procesare și necesarul de memorie de lucru.
- Convoluție separabilă în profunzime (Depthwise Separable Convolution) – Variantă optimizată a convoluției clasice din rețelele neurale, în care filtrarea se realizează separat pe fiecare canal de intrare, reducând semnificativ numărul de parametri și operații.
- Păduri aleatorii (Random Forests) – Metodă de învățare automată bazată pe un ansamblu de arbori de decizie, utilizată pentru clasificare și regresie. Fiecare arbore generează o predicție, iar rezultatul final este stabilit prin „vot” majoritar. Este apreciată pentru echilibrul între precizie și eficiență.
- End-to-End – Arhitectură AI în care modelul procesează datele de la intrare până la ieșire într-un flux complet, fără etape intermediare explicite de preprocesare sau extracție manuală a caracteristicilor.
- VAD (Voice Activity Detection) – Detectarea activității vocale; tehnică utilizată pentru identificarea momentelor în care un semnal audio conține vorbire umană, permițând economisirea de energie și resurse de procesare.