

Piața AI trece printr-o schimbare de paradigmă. În mod tradițional, procesarea modelelor AI era realizată în principal în cloud. Dispozitivele finale colectau date de la senzori, le transmiteau în cloud pentru inferență și decizie, iar rezultatele erau trimise înapoi către dispozitive. Această abordare genera latență ridicată, un consum energetic mare, riscuri de securitate și necesita o lățime de bandă semnificativă pentru transmiterea datelor. Potrivit IDC, în 2025 aproximativ 79,4 ZB de date vor fi trimise de la dispozitivele IoT către cloud.
De ce Edge AI?
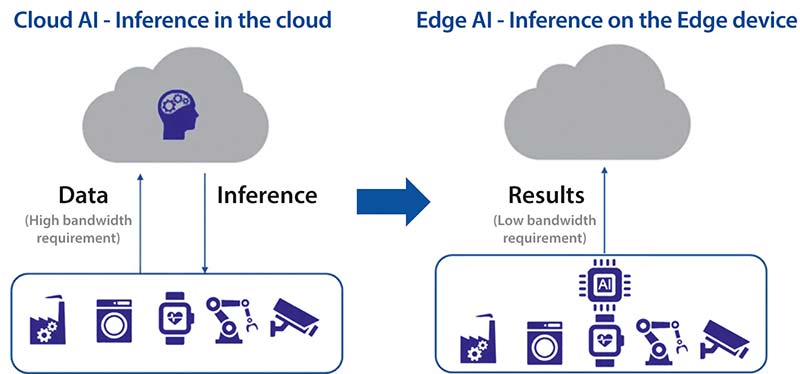
Figura 1: Trecerea de la inferența în cloud la inferența la marginea rețelei. (Sursă imagine: Renesas)
Toate aceste limitări au condus la o tendință puternică de a muta inferența AI la marginea rețelei. Edge AI permite răspunsuri rapide în timp real, oferă confidențialitate și securitate sporite și elimină dependența de conexiunea la cloud, reducând astfel latența și costurile asociate. În plus, scade semnificativ consumul de energie, aspect esențial pentru aplicații IoT și dispozitive alimentate de la baterii. Prin urmare, Edge AI aduce avantaje precum autonomie, latență redusă, eficiență energetică, costuri mai mici cu lățimea de bandă și un nivel ridicat de securitate – beneficii care îl transformă într-o soluție ideală pentru aplicațiile emergente.
Există numeroase soluții dedicate pieței Edge AI. Alegerea între un microprocesor și un microcontroler pentru implementarea AI depinde exclusiv de cerințele aplicației. Microprocesoarele sunt potrivite pentru aplicații complexe, care necesită o putere de procesare ridicată, în timp ce microcontrolerele reprezintă o opțiune ideală pentru aplicații cu consum redus de energie și sensibile la costuri, unde procesarea în timp real și eficiența energetică sunt esențiale.
Nevoia de acceleratoare AI dedicate
Procesarea rețelelor neurale presupune numeroase operații de algebră liniară, produse scalare, multiplicări, convoluții și transpoziții de matrice executate rapid și în paralel. Toate acestea necesită o putere de calcul ridicată din partea procesoarelor. Producătorii de microcontrolere introduc acum dispozitive care includ nuclee CPU avansate, cu îmbunătățiri destinate operațiunilor DSP și AI/ML, precum extensiile vectoriale Helium pentru nucleul Arm Cortex-M85. De asemenea, acești producători integrează o unitate de procesare neurală (NPU) în microcontroler, proiectată pentru accelerarea sarcinilor de inferență AI.
Avantajele NPU-urilor:
- Performanță superioară pentru procesarea AI/ML – Un NPU include hardware dedicat pentru operațiile fundamentale ale rețelelor neurale, precum înmulțirile și convoluțiile matriciale, executate mai eficient și cu o latență mai mică decât pe nucleul CPU. NPU-urile sunt optimizate pentru aritmetică pe întregi cu precizie redusă (8/4 biți), utilizată în mod obișnuit în modelele AI, ceea ce scade complexitatea, utilizarea memoriei și consumul de energie, fără a compromite precizia inferenței.
- Partiționare eficientă a sistemului – NPU-urile gestionează sarcinile AI și degrevează unitatea centrală de procesare, care poate astfel să se ocupe de pre- și post-procesarea datelor AI, de codul aplicației și de alte funcții ale sistemului, precum securitatea, interfețele senzorilor și comunicațiile. Rezultatul este o performanță generală îmbunătățită a sistemului.
- Consum redus de energie – NPU-ul poate procesa modele cu un consum energetic mult mai redus decât nucleul CPU, ceea ce îl face ideal pentru dispozitivele edge, unde eficiența energetică este esențială.
- Securitate sporită – NPU-urile permit rularea locală a inferenței și a procesului decizional pe dispozitivul edge, reducând la minimum transmiterea datelor către cloud și asigurând astfel confidențialitatea și integritatea datelor.
Pentru ca tehnologia Edge AI să beneficieze de un consum redus de energie, este necesar un microcontroler cu accelerare AI complet integrată și de înaltă performanță, capabil să ofere inferență extrem de sigură, un consum energetic scăzut și timp de răspuns rapid în aplicațiile în timp real.
Prezentarea microcontrolerului RA8P1 cu accelerare AI
Dispozitivele RA8P1 sunt primele microcontrolere cu unul sau două nuclee dotate cu accelerare AI de la Renesas și sunt realizate pe procesul avansat TSMC 22nmULL. Acestea combină nucleele CPU Arm® Cortex®-M85 (CM85) și Cortex-M33 (CM33), de înaltă performanță, cu procesorul de rețea neurală (NPU) Arm Ethos™-U55, pentru a oferi o creștere semnificativă a performanței în AI/ML, DSP și procesare scalară – o configurație ideală pentru aplicații Edge AI și IoT.
Aceste microcontrolere înalt integrate oferă o performanță brută impresionantă, de peste 7300 CoreMarks, o performanță AI de 256 GOPS și, datorită memoriei mari și setului bogat de periferice, susțin aplicații exigente de voce, viziune AI și analiză în timp real. Rezultatul este o capacitate de procesare cu ordine de mărime superioară față de performanța unui singur nucleu CPU.
Microcontrolerele RA8P1 dual-core îmbunătățesc semnificativ performanța aplicațiilor AI, oferind o putere de procesare mai mare, o partiționare eficientă a sarcinilor între cele două nuclee, timpi de răspuns îmbunătățiți și eficiență energetică ridicată. În plus, includ securitate avansată, memorie imuabilă și TrustZone, pentru a permite dezvoltarea unor aplicații AI cu un nivel ridicat de siguranță.
Îmbunătățirea performanței inferenței AI cu Ethos-U55 NPU
Procesorul neural Arm Ethos-U55 integrat în RA8P1 este un accelerator dedicat, optimizat pentru operațiile fundamentale ale rețelelor neurale – precum multiplicările și convoluțiile matriciale – executate mai eficient și cu un consum redus de energie comparativ cu nucleul CPU. NPU-ul este proiectat să funcționeze perfect alături de nucleele Cortex-M, descărcând sarcina procesorului principal și oferind suport pentru toți operatorii utilizați în CNN și RNN.
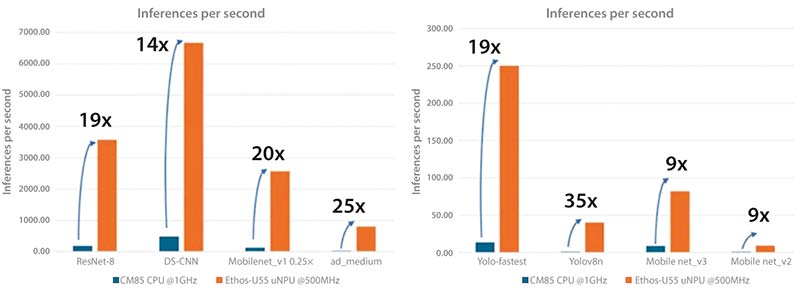
Figura 2: Creștere semnificativă a performanței AI cu NPU Ethos-U55 în comparație cu nucleul CPU. (Sursă imagine: Renesas)
Acesta acceptă ponderi pe 8 biți și activări pe 8/16 biți și utilizează memoria SRAM de sistem și memoria nevolatilă prin intermediul a două interfețe master AXI de 64 biți. De asemenea, folosește mecanisme de compresie și decompresie a ponderilor pentru a accelera inferența și a reduce necesarul de memorie. Suportă și un mod de rezervă, în care operatorii neacceptați de NPU sunt rulați pe nucleul Cortex-M, accelerat în software folosind CMSIS-NN.
Ethos-U55 este compatibil cu cele mai utilizate arhitecturi de rețele neurale, precum DS-CNN, ResNet, MobileNet, Inception sau Wav2Letter.
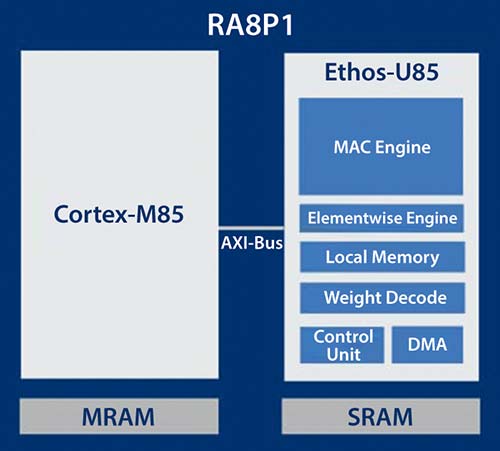
Figura 3: Arhitectura NPU Ethos-U55 (Arm) și interfețele de sistem. (Sursă imagine: Renesas)
Renesas a demonstrat cu succes creșterea performanței de inferență folosind microcontrolerele RA8P1 cu Ethos-U55, prin mai multe cazuri de utilizare AI/ML, evidențiind o îmbunătățire semnificativă a performanței NPU-ului în comparație cu nucleul CPU.
Modele utilizate:
- Clasificarea imaginilor – ResNet8, MobileNet v2, MobileNet v3
- Identificarea cuvintelor cheie – DS-CNN
- Cuvinte de activare vizuale (Visual Wake Words) – MobileNet v1
- Detectarea obiectelor – Yolo_fastest, Yolov8N
- Detectarea anomaliilor – ad_medium
Dezvoltare accelerată a aplicațiilor cu RUHMI Framework
Soluția RA8P1 AI include RUHMI Framework, primul mediu complet de dezvoltare AI al Renesas pentru microcontrolere și microprocesoare, integrat în Renesas e2studio IDE pentru optimizarea și implementarea modelelor de rețele neurale, într-o manieră independentă de framework-ul utilizat. RUHMI permite optimizarea modelului, cuantificarea și conversia într-un format compatibil cu microcontrolerul.
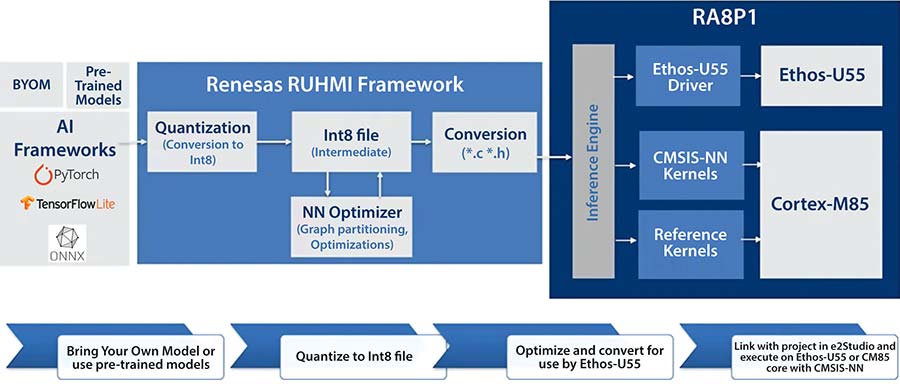
Figura 4: Flux de lucru AI utilizând cadrul Renesas RUHMI. (Sursă imagine: Renesas)
Acesta oferă toate instrumentele, API-urile, generatorul de cod și mediul de execuție necesare pentru implementarea unui model pre-antrenat pe RA8P1. Sunt incluse suportul nativ pentru framework-urile ML utilizate frecvent – TensorFlow Lite, PyTorch și ONNX – precum și exemple de aplicații gata de utilizare și modele optimizate pentru RA8P1.
Flux de lucru AI tipic cu RUHMI:
- Optimizarea și compilarea modelului (Offline): Un model AI pre-antrenat este importat prin intermediul framework-urilor utilizate frecvent, precum TensorFlow Lite, cuantificat într-un format intermediar Int8 și optimizat pentru execuția pe nucleul NPU sau CPU. Modelul este apoi compilat într-un format compatibil cu microcontrolerul (de regulă fișiere *.c/*.h) care poate fi executat de NPU.
- Introducerea și preprocesarea datelor: Datele brute de intrare (imagine de la cameră, audio de la microfon) sunt captate de microcontroler. Acestea sunt apoi preprocesate de CPU pentru a fi scalate și formatate în vederea introducerii în modelul AI.
- Execuție pe NPU: Nucleul CPU transmite datele de intrare preprocesate și fluxul de comenzi al modelului AI compilat către NPU pentru execuție. NPU-ul interpretează fluxul de comenzi și, utilizând datele de intrare și ponderile modelului (de obicei stocate în memoria locală), procesează fiecare strat al rețelei neurale, trimițând rezultatele intermediare către straturile adiacente.
- Ieșire și post-procesare: După ce NPU-ul a procesat toate straturile rețelei neurale, acesta transmite rezultatele inferenței – de exemplu, coordonatele casetei de delimitare și clasificarea unui obiect sau un semnal de tip „cuvânt de activare detectat” – înapoi către CPU-ul principal, care se ocupă de post-procesarea finală și de acțiunile necesare (suprapunerea casetelor de delimitare pe imagine, declanșarea unei acțiuni, trimiterea datelor către cloud etc.).
Aplicații AI activate de RA8P1
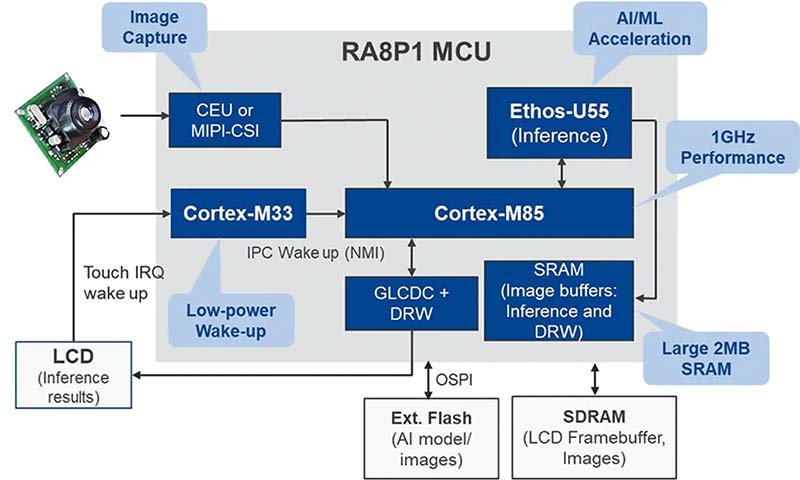
Figura 5: Diagrama bloc a sistemului de clasificare a imaginilor. (Sursă imagine: Renesas)
Datorită performanței ridicate de inferență, consumului redus de energie și capabilităților de procesare în timp real, RA8P1 este ideal pentru o gamă largă de aplicații AI din diverse segmente de piață, precum:
- Voce AI – Identificarea cuvintelor cheie, recunoașterea vocii, recunoașterea vorbirii, identificarea vorbitorului
- Viziune AI – Detectarea obiectelor, clasificarea imaginilor, recunoașterea gesturilor, recunoașterea feței, analiza imaginilor, monitorizarea șoferului/vehiculului
- Analiză în timp real – Detectarea anomaliilor, analiza vibrațiilor, întreținere predictivă
- Aplicații multimodale – HMI inteligent cu capabilități vocale și vizuale, camere de supraveghere îmbunătățite, robotică cu intrări vizuale și auditive pentru detecția mediului și interacțiune
În secțiunea următoare, vom analiza două exemple de implementări AI pe RA8P1.
Exemplu de aplicație 1: Clasificarea imaginilor pe RA8P1
Figura de mai jos prezintă o aplicație AI de clasificare a imaginilor, care analizează o imagine de intrare și îi atribuie o etichetă sau o categorie prestabilită. Modelul rețelei neurale este antrenat iterativ pe un set amplu de imagini etichetate, până când precizia de predicție devine foarte ridicată. Acest model pre-antrenat poate fi implementat pe microcontrolerul RA8P1.
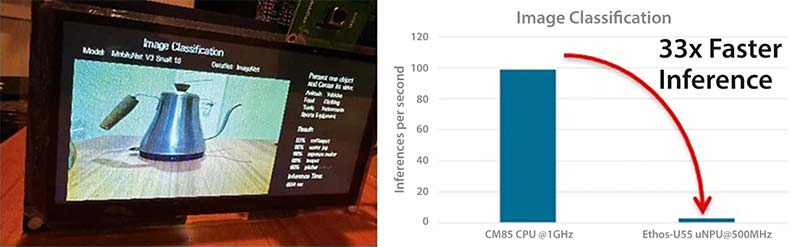
Figura 6: Clasificarea imaginilor pe RA8P1 și comparația performanțelor, NPU vs. CPU. (Sursă imagine: Renesas)
Pentru inferență, o nouă imagine de intrare este transmisă modelului și parcurge straturile rețelei antrenate. Stratul de ieșire furnizează distribuția probabilistică pentru toate categoriile, iar categoria cu probabilitatea cea mai mare este atribuită imaginii ca etichetă finală. Rezultatele inferenței (etichetă și probabilitatea asociată) pot fi apoi afișate local sau transmise în cloud.
În implementarea prezentată, se observă o îmbunătățire de 33 de ori a vitezei de inferență cu Ethos-U55, comparativ cu utilizarea nucleului CPU, și un consum energetic de 62 mA la rularea inferențelor la 1000 fps (incluzând accesul la memoria externă).
Clasificarea imaginilor poate fi utilizată într-o gamă largă de aplicații, precum:
- Securitate – identificarea armelor, recunoașterea persoanelor, detectarea anomaliilor
- Comerț cu amănuntul – crearea de cataloage de produse pe categorii, gestionarea stocurilor
- Agricultură – identificarea bolilor culturilor, clasificarea plantelor
- Orașe inteligente – identificarea semafoarelor, a semnelor de circulație și a pietonilor
- Electrocasnice inteligente – identificarea obiectelor din interiorul frigiderului
Exemplu de aplicație 2: Sistem de monitorizare a șoferilor utilizând RA8P1
Această aplicație prezintă un sistem de monitorizare a șoferului (DMS – Driver Monitoring System), o soluție de siguranță în habitaclu care îmbunătățește siguranța rutieră în toate aspectele legate de deplasarea vehiculului. Sistemul DMS dezvoltat de Nota-ai rulează mai multe modele pentru a detecta șoferii neînregistrați, somnolența, utilizarea telefonului mobil și alte tipuri de distragere, precum fumatul.
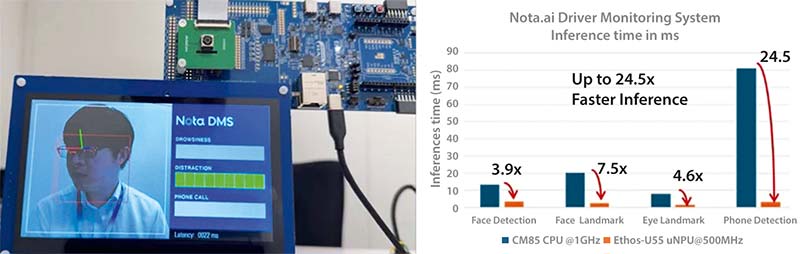
Figura 7: Sistem de monitorizare a șoferului utilizând RA8P1 și comparație a performanței, NPU vs. CPU. (Sursă imagine: Renesas)
Folosind RA8P1, se observă o creștere de 4x–24x a performanței de inferență pentru cele patru modele utilizate în această aplicație: detectarea feței, localizarea reperelor faciale (face landmarks), localizarea reperelor oculare (eye landmarks) și detectarea telefonului. Consumul mediu de curent măsurat în timpul rulării tuturor celor patru modele a fost de 86 mA.
DMS poate fi integrat în camere de bord, înregistratoare de date ale vehiculului și sisteme avansate de monitorizare a șoferului.
Utilizarea optimă a resurselor microcontrolerului RA8P1 în aplicațiile de Viziune AI:
1. Achiziție eficientă a imaginilor de intrare prin senzorul de imagine
RA8P1 include o interfață MIPI CSI-2 cu unitate de scalare a imaginii sau interfața paralelă CEU de 16 biți pentru captarea datelor brute de intrare.
2. Procesare de inferență de înaltă performanță cu NPU Ethos-U55
Acceleratorul AI Ethos-U55 primește imaginile preprocesate de interfața camerei MIPI CSI-2 sau CEU și procesează modele AI complexe mai eficient și cu un consum energetic redus, comparativ cu nucleul CPU.
3. Procesare accelerată a aplicațiilor cu nucleele CPU Arm Cortex-M85 și Cortex-M33
Nucleul CM85 de 1 GHz, cu extensii vectoriale Arm Helium, este utilizat pentru pre- și post-procesarea datelor de intrare și a rezultatelor inferenței. Operatorii neacceptați de Ethos-U55 pot fi executați de CM85 în modul de rezervă. Cu inferența descărcată pe NPU, CPU-ul CM85 poate fi folosit integral pentru codul aplicației, inclusiv pentru sarcini cu calcul intensiv.
Nucleul Cortex-M33 de 250 MHz de pe variantele RA8P1 dual-core poate fi utilizat pentru sarcini auxiliare și servicii cu consum redus de energie.
4. Stocarea eficientă a imaginilor, ponderilor modelelor și activărilor prin memoria integrată și interfețele de memorie
Memoria integrată MRAM de 1 MB și SRAM de 2 MB sunt esențiale pentru stocarea ponderilor modelelor AI, a imaginilor și a rezultatelor intermediare.
Interfețele de memorie externă cu debit ridicat (OSPI cu XIP și decriptare în timp real, respectiv SDRAM pe 32 de biți) pot fi utilizate pentru modele mai mari.
5. Periferice grafice avansate pentru procesare grafică și HMI
Controlerul LCD grafic (cu interfețe paralele sau MIPI DSI) și motorul grafic 2D pot fi utilizate pentru redarea imaginilor și a rezultatelor inferenței pe ecranul LCD.
6. Opțiuni flexibile de conectivitate
Există mai multe opțiuni de conectivitate pentru a transmite rezultatele inferenței, imaginile sau alertele/notificările fie către dispozitive locale, fie către cloud, pentru stocare sau analiză.
Concluzie
Aplicațiile Edge AI beneficiază semnificativ de utilizarea microcontrolerelor cu accelerare AI, acestea permițând dezvoltarea unor soluții în care performanța în timp real, consumul redus de energie și securitatea sunt factori critici. Integrarea unui NPU în microcontrolerele cu consum redus de energie a reprezentat o schimbare majoră în peisajul soluțiilor AI. Noile microcontrolere RA8P1 reduc considerabil latența, asigură confidențialitatea datelor și minimizează consumul de energie, fiind ideale pentru aplicații alimentate de la baterii. Întregul proces de dezvoltare este susținut de framework-ul complet RUHMI al Renesas, care permite optimizarea și implementarea eficientă a modelelor AI pe hardware-ul RA8P1.
Pentru mai multe informații, vizitați: https://www.renesas.com/en/products/ra8p1
 Autor
Autor
Kavita Char,
Principal Product Marketing Manager
Glosar de termeni
Aritmetică pe întregi (8/4 biți) – Tip de procesare numerică utilizată în acceleratoarele AI, în care operațiile sunt efectuate cu valori întregi pe 8 sau 4 biți, reducând consumul energetic și memoria necesară, fără a compromite precizia inferenței.
Visual Wake Words (cuvinte de activare vizuale) – Modele AI optimizate pentru dispozitive low-power, utilizate pentru detectarea unui obiect sau tipar vizual specific, declanșând o acțiune fără procesare continuă.
NPU (Neural Processing Unit) – Accelerator hardware dedicat procesării modelelor AI/ML, optimizat pentru operații de tip convoluție, înmulțiri matriciale și execuție paralelă a straturilor de rețea neurală.
Face Landmarks / Eye Landmarks (repere faciale / repere oculare) – Puncte cheie detectate pe față sau în zona ochilor, utilizate pentru urmărirea poziției, expresiilor și stării șoferului în aplicațiile de monitorizare.
Fallback Mode (mod de rezervă) – Mecanism prin care operatorii neacceptați de NPU sunt executați pe nucleul CPU, accelerat software prin biblioteci precum CMSIS-NN.
XIP (Execute In Place) – Tehnică ce permite executarea codului direct din memoria externă (ex.: OSPI Flash), fără a-l copia în RAM, reducând latența și consumul de memorie.