

 Niciun dispozitiv electronic nou nu este considerat „high-tech” în zilele noastre dacă nu prezintă cel puțin o formă de „inteligență artificială” sau AI. Aplicațiile cu adevărat sofisticate necesită cantități uimitoare de putere de procesare, așadar, se poate face ceva cu un microcontroler modest? Vom începe mai întâi cu câteva elemente de bază.
Niciun dispozitiv electronic nou nu este considerat „high-tech” în zilele noastre dacă nu prezintă cel puțin o formă de „inteligență artificială” sau AI. Aplicațiile cu adevărat sofisticate necesită cantități uimitoare de putere de procesare, așadar, se poate face ceva cu un microcontroler modest? Vom începe mai întâi cu câteva elemente de bază.
Una dintre noile generații de plăci de microcontroler cu hardware optimizat pentru integrarea Inteligenței Artificiale în dispozitivele de margine.
(© Eta Compute) ▶
Ce este AI (inteligența artificială)?
O problemă majoră întâmpinată atunci când încercăm să explicăm sau să discutăm despre inteligența artificială este că toată lumea – indiferent de pregătire – are o părere fermă (de regulă diferită) cu privire la acest subiect. Acest lucru se datorează faptului că nu există o definiție agreată cu limite sau granițe. Prin urmare, un om de rând va tinde să-și imagineze că tehnologia actuală este la doar un mic pas de a ne oferi mașini care gândesc cu adevărat, care ne iau slujbele, sau care sunt capabile să se reproducă singure și, în cele din urmă, să ne vadă pe noi, constructorii lor, ca ființe extrem de inferioare, cu consecințe inevitabil rele. Se poate întâmpla, dar această viziune distopică provine dintr-o caracteristică majoră a creierului uman pe care inteligență artificială curentă nu o are: imaginația.
Întrebați un om de știință sau matematician care lucrează la un AI despre caracteristicile inteligenței artificiale și veți fi copleșiți de un jargon de neînțeles, care nu vă va face mai înțelepți, dar vă va convinge că trebuie să fie cu adevărat avansat, deoarece nu ați înțeles un cuvânt. Întrebați un inginer și răspunsul va fi probabil nepoliticos, deoarece șeful șefului lor a citit totul despre inteligența artificială într-o revistă de management și dorește ca aceasta să fie inclusă în toate produsele viitoare. Și oricum, cei de la Marketing insistă asupra faptului că etichetele vechi precum „Smart” sau „Intelligent” trebuie înlocuite cu „Powered by AI” sau vânzările vor cădea “ca de pe o stâncă”. Prea cinic? Nu credeți?
În concluzie, unde suntem cu o definiție? Din perspectiva ingineriei, conceptul actual de inteligență artificială se învârte în jurul unui algoritm foarte puternic de detectare a modelelor bazat pe o versiune artificială a rețelei neuronale găsite în creierul uman. Rețeaua neuronală artificială (ANN) (n.red.: pe scurt, rețea neurală) este de obicei rulată în simulare pe un calculator convențional multi-nucleu. În cele din urmă, scopul este de a realiza ANN în hardware folosind o rețea de neuroni artificiali care comunică între ei folosind metoda utilizată de creier de a trimite impulsuri electrice temporizate sau „Spikes”. De aici și termenul de rețea neurală Spiking (SNN). Există trei sarcini principale implicate în crearea unei rețele neurale funcționale: proiectarea unui model de rețea pentru a se potrivi aplicației, antrenarea rețelei și, în cele din urmă, deducerea (extragerea) sau inferența rezultatelor din modelul de rețea.
Modelul
O formă specială de ANN (rețea neuronală artificială) este cunoscută sub numele de Rețea neurală convoluțională (CNN) și constă dintr-o serie de perceptroni interconectați (figura 1), bazată pe tehnologia digitală standard. Acest exemplu simplu are un strat cu patru intrări, două straturi intermediare sau „ascunse” și un strat cu două ieșiri. Cum decideți numărul de intrări, ieșiri și, mai important, numărul de straturi ascunse, atunci când începeți un proiect de la zero?
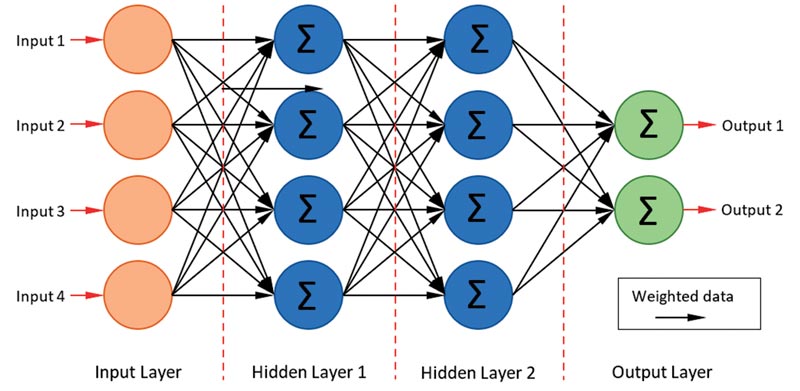
Figura 1: Rețea neurală simplă
Primele două sunt relativ ușoare. Exemplu: Pentru detectarea / clasificarea obiectelor în cadrul datelor de imagine 320 × 200 pixeli, RGB, primite de la o cameră digitală, veți avea nevoie de 320 × 200 × 3 = 192.000 de intrări! Stratul de ieșire va reflecta numărul de obiecte pe care rețeaua va fi antrenată să le recunoască. Deci, să zicem, unsprezece ieșiri pentru zece obiecte, inclusiv una pentru „nimic recunoscut”. Straturile ascunse vor începe cel puțin conținând 192.000 de noduri, dar marea întrebare este câte straturi sunt necesare? În acest model „dens” cu fiecare nod dintr-un strat conectat printr-o legătură ponderată la fiecare alt nod din următorul strat, este necesară o cantitate mare de procesare la nivel scăzut. Fiecare nod din straturile ascunse va avea nevoie de 192.000 de înmulțiri pentru început (unul pentru fiecare legătură ponderată) și, dacă formatul numeric este în virgulă mobilă pe 32-biți, puteți vedea că orice procesor încorporat va avea nevoie de cel puțin o unitate cu virgulă mobilă (FPU).
Imaginați-vă puterea de procesare necesară pentru a conduce o rețea antrenată să recunoască sute de obiecte diferite în videoclipurile HD, cu cadre de intrare modificate la 30 fps. Și fiecare cadru ar putea conține zeci de obiecte. Acesta este genul de performanță necesară pentru un sistem de conducere autonomă a unui vehicul … Dacă aceasta este aplicația ML pe care o aveți în minte, atunci veți avea nevoie de un sistem multiprocesor foarte scump; unul de genul care își măsoară performanța în mulți petaFLOPS (1015 operații în virgulă mobilă pe secundă). Tesla a recunoscut că, în cazul în care autopilotul autoturismelor autonome va merita vreodată să fie realizat, va avea nevoie de exaFLOPS (1018 FLOPS) doar pentru a-l antrena. Ei au anunțat dezvoltarea propriului lor cip Dera 362 teraFLOPS (1012 FLOPS), care va fi combinat cu alți 119 pe o „placă/structură de antrenament”. Cu 25 de plăci “împrăștiate” prin mai multe compartimente, acestea ar trebui să ajungă la nivelul exaFLOPS. Ar trebui să fie suficient. Probabil.
Acesta este MegaML, ce ziceți de TinyML?
Am furnizat numerele de mai sus pentru a genera ideea că inteligența naturală este mult superioară, în toate privințele, celei mai sofisticate mașini de pe planetă. În ciuda tuturor cantităților mari de energie electrică consumată de calculator, există probabilitatea ca sistemele de analiză de imagine bazate pe CNN, doar cu intrare video, să nu fie niciodată suficient de precise pentru vehiculele autonome. Având în vedere acest lucru, ce puteți face cu un singur SBC (computer pe o singură placă) bazat pe microprocesor? De fapt, destul de multe – doar să nu existe prea multe pretenții. TinyML provoacă mult entuziasm în lumea IoT (Internetul Lucrurilor). Conceptul de a conecta milioane de aparate de uz casnic și alte surse de date la „Cloud” prin intermediul Internetului pare o idee grozavă. Datele ar putea fi colectate de aceste dispozitive, procesate de serverele Cloud și rezultatele sau semnalele de control returnate. Din păcate, volumul mare de procesare, ca să nu mai vorbim de problemele de securitate cu monitoarele medicale/de fitness, de exemplu, adaugă mai degrabă o întârziere asupra lucrurilor. Asta până când cineva s-a gândit să facă o parte din prelucrarea datelor la nivel local, înainte de a o trimite în cloud – așa-numita prelucrare la margine – procesare „Edge”.
Un exemplu de inteligență artificială ‘la margine’
Fabricile automatizate care stau la baza Industrie 4.0 vor fi pline de mașini care trebuie menținute să funcționeze la randament maxim. Deoarece nu vor exista operatori umani care să identifice semne de avarie iminentă, mașinile trebuie să fie monitorizate de computere folosind senzori electronici. Este puțin probabil ca un singur senzor sau chiar un tip de senzor să poată indica în mod fiabil o stare de defecțiune. Deci, un motor electric care urmează să sufere de defectarea unui rulment poate începe să emită un sunet de frecvență înaltă la anumite frecvențe coroborate cu rotația arborelui. Acest lucru ar putea progresa la vibrații de joasă frecvență însoțite de o creștere a curentului de armătură, o scădere a vitezei de rotație și o creștere a temperaturii carcasei.
Toate aceste modificări ar putea fi foarte mici inițial și să treacă neobservate de un monitor uman, până când devine prea târziu pentru acțiuni de remediere, cum ar fi aplicarea unei ungeri cu ulei! Calculatorul de monitorizare procesează semnale de la accelerometrele și senzorii de temperatură atașați pe carcasele de rulmenți, senzorii de temperatură ambientală și microfoane în combinație cu datele existente de la tahometrele de arbori și senzorii de curent amplasați pe alimentare. Programarea computerizată standard bazată pe o structură IF… THEN… ELSE ar putea fi utilizată pentru a da sens tuturor datelor, dar AI oferă o alternativă în care datele reale preluate de la mașini reale sunt folosite pentru a antrena un CNN.
Avantajul utilizării AI în aceste circumstanțe este că, având în vedere un set complet de date de instruire, rețeaua nu trebuie să detecteze doar toate tiparele de intrare cunoscute care duc la eșecuri, ci ar putea localiza noi modele mai subtile trecute cu vederea de inspecția umană. O privire asupra modelului generat al distribuției ponderate ar putea dezvălui intrări redundante, care contribuie cu puțin sau cu nimic la analiză. Dacă intrările utilizate produc semnale fals pozitive sau negative, acest lucru poate sugera că este nevoie de un senzor suplimentar.
În mod clar, TinyML semnifică exact ceea ce implică numele său: este proiectat pentru aplicații relativ mici, cu puține intrări / ieșiri și un număr redus de obiecte / condiții de recunoscut. Acest lucru îl face ideal pentru a face „Lucrurile” embedded mult mai inteligente, reducând sarcina pe legăturile și serverele de comunicații de pe Internet.
Hardware-ul
Am arătat deja că detectarea / clasificarea obiectelor în videoclipuri în timp real necesită niveluri de putere de procesare specifice super-computerelor. Proiectele care nu sunt foarte ambițioase pot fi rulate pe unele dintre plăcile performante, dar economice, de tip SBC sau cu microcontroler ARM Cortex-M, de pe piață. Detectarea obiectelor prin analiza de imagine cu rezoluție scăzută se încadrează în capabilitățile Raspberry Pi 4 (182-2096), BeagleBone AI, Sony SPRESENSE (178-3376), Arduino Nano 33 Sense (192-7592) și chiar Raspberry Pi Pico (212 -2162). Primele două dispun de procesare destul de puternică care rulează versiuni ale sistemului de operare Linux. Al doilea produs este o placă cu microcontroler mai puțin puternică, dar care dispune de mulți senzori integrați pe placă. AI de bază poate fi rulată și pe microcontrolere pe 32-biți fără FPU și minimum 16 KB de memorie – Raspberry Pi Pico se încadrează în această categorie.
Când lucrați cu procesoare cu consum redus de energie, există anumiți pași care pot fi luați în considerare pentru a accelera lucrurile, ca de exemplu:
- Utilizarea numerelor întregi de 8 biți în loc de virgulă mobilă pe 32 de biți. Această pierdere a rezoluției va afecta grav precizia de detectare pe rețele foarte mari, cum ar fi sistemul de conducere autonomă. Dar numerele pe 8 biți vor fi mai mult decât adecvate pentru aplicațiile capabile de implementare pe un microcontroler.
- Pot fi inserate straturi de reducere a dimensiunilor spațiale ale reprezentării (pooling layers) pentru a reduce numărul de noduri din straturile ulterioare. Tehnica este frecvent utilizată cu date de imagine în care caracteristicile necesare pentru detectare sunt puternice, iar reducerea rezoluției le face mai slabe, dar totuși recunoscute de straturile ulterioare mai mici.
- Când procesați o imagine color RGB (adică trei intrări), aceasta poate îmbunătăți efectiv detectarea dacă este utilizat un singur canal de culoare.
Antrenarea modelului
În acest moment, mediul dominant de dezvoltare AI este TensorFlow de la Google. Destinat inițial aplicațiilor care au nevoie de supercalculatoare, există acum o versiune redusă pentru sisteme mai modeste numită Tensorflow Lite. O versiune mai redusă este acum disponibilă pentru microcontrolere cu sau fără FPU-uri și un minim de 16 KB de memorie. În mod nesurprinzător, se numește TensorFlow Lite pentru microcontrolere. Antrenarea unei CNN pentru sortarea lucrurilor nu este o sarcină complicată; antrenarea acesteia pentru a nu face greșeli în situații de viață sau de moarte este mult mai dificilă. De fapt, este atât de grea încât niciun sistem actual de detectare a obiectelor dezvoltat pentru mașinile fără șofer nu este aproape de atingerea unui nivel acceptabil de încredere. Un număr de accidente mortale din ultimii ani, cauzate de interpretarea incorectă a datelor vizuale, demonstrează acest lucru. Din fericire, rețelele TinyML, fiind mici, sunt mult mai ușor de antrenat. Instruirea pentru rețele mari este de obicei efectuată de instrumente bazate pe cloud din cauza nevoii de computere extrem de puternice, dar pentru TinyML unele instrumente vor rula pe un computer local.
Procesul de instruire este înșelător de simplu. Deci, pentru aplicația de diagnosticare a mașinii:
- Colectați un număr mare de seturi de date ale senzorilor fiecare având ,,etichetă” în funcție de faptul că provine de la o mașină despre care se știe că are probleme / funcționează defectuos sau de la una care funcționează normal. Dacă rețeaua are mai multe ieșiri pentru raportarea diferitelor tipuri de defecțiuni, atunci toate seturile de date de intrare corespunzătoare trebuie să fie astfel etichetate. Este foarte important să aveți multe exemple pentru fiecare proprietate care trebuie detectată.
- Rețeaua simulată este inițializată în mod normal cu valori aleatorii ale distribuției ponderate. Valorile nu sunt nule, deoarece dacă toate toți multiplicatorii ar fi zero, atunci nimic nu se va schimba când începe antrenamentul!
- Programul de instruire prezintă un set de date de intrare la intrarea CNN, rulează simularea și verifică ieșirea pentru a vedea dacă se potrivește cu răspunsul etichetat (corect). Dacă nu, valorile rețelei sunt ajustate și rețeaua rulează din nou. Dacă este necesar, acest proces se repetă până când rețeaua „converge” către răspunsul corect. Aceasta este o simplificare masivă, dar descrie pe larg procesul de învățare cunoscut sub numele de propagare inversă.
În practică, procesul de instruire poate dura mult timp, cu multă intervenție umană pentru a modifica parametrii până când rețeaua oferă rezultate acceptabile. Pentru a o testa corect, datele noi de intrare care nu sunt folosite pentru antrenarea rețelei sunt rulate prin simulare. Acest lucru ar trebui să fie suficient pentru a verifica dacă o rețea TinyML este suficient de „inteligentă” pentru sarcină. Cei care lucrează la detectarea obiectelor pentru vehicule autonome au descoperit că un sistem care oferă o precizie de 95% în laborator nu poate gestiona mai bine de 50% pe drum. Se pare că cel puțin pentru această aplicație nu vom avea niciodată suficiente date de antrenament.
Deducerea unui rezultat
Odată „antrenată”, faza de „Deducere” începe atunci când rețelei îi sunt afișate date ‘live’ și caută modele care se potrivesc cu cele generate de antrenamentul său. Rezultatele sunt deduse mai degrabă decât calculate și sunt prezentate în termeni de probabilitate a unei potriviri. Dacă totul funcționează în simulare, rețeaua poate fi introdusă în memoria microcontrolerului și testată într-un sistem în timp real.
Trișare, prejudecată și perspectivă
În ciuda faptului că nu au nimic asemănător cu capacitatea unui creier natural, CNN-urile pot prezenta comportamente care la început pot părea puțin deranjante. În primul rând, pot „înșela antrenamentul”, oferind răspunsul „corect”, dar din motive greșite. Acest lucru se poate întâmpla atunci când datele voastre de antrenament nu sunt suficient de variate. De exemplu, un robot de depozit poate fi instruit să recunoască cutiile de carton verzi. Deci, setul de antrenament conține imagini de toate formele și dimensiunile cutiei verzi. Prima oară pe teren, robotul alege un lucrător din depozit. De ce? Pentru că el sau ea poartă salopetă verde. În timp ce era instruită, rețeaua a „dedus” că orice culoare verde trebuie să fie o cutie – o „scurtătură” drăguță, dar potențial fatală.
În al doilea rând, din motive similare, mașina poate produce un rezultat părtinitor. Acest lucru s-a întâmplat cu bazele de date de cazier judiciar încărcate cu un număr insuficient de înregistrări ale persoanelor de culoare.
În al treilea rând, în sfârșit, o caracteristică pozitivă: perspectiva. CNN-urile se pricep foarte bine la depistarea tiparelor în volume mari de date greu de procesat de creierul uman: observând modele subtile de comportament care ar putea identifica un criminal în serie într-o vastă bază de date a poliției, de exemplu. Sau găsirea tendințelor emergente de sănătate într-o populație numeroasă prin analizarea datelor (anonimizate) din ceasurile de fitness.
Concluzie
Rețelele neuronale artificiale masive care rulează pe supercalculatoare pot acapara prim-planul atunci când îi bat pe oameni la jocuri de societate precum șah sau Go. Este posibil ca rețelele TinyML mult mai mici să nu aibă o putere suficientă pentru a juca jocuri sau pentru a face noi descoperiri în știință sau medicină, dar pot salva viața unei ființe umane sau pot detecta o mașină aflată în dificultate făcând câteva deducții simple pe baza intrărilor de la senzori. De asemenea, este mai puțin probabil să facă deducții catastrofale, precum detectarea eronată a unui camion articulat în fața mașinii în loc de un pod peste drum. Multe dispozitive hardware recent dezvoltate țintesc modulul de calcul TinyML / Edge, despre care toată lumea crede că va fi următorul lucru important. Cipul ECM3532 de la Eta Compute este creat pentru AI embedded și se bazează pe un nucleu ARM Cortex-M3 care operează cu un nucleu NXP DSP. Un alt dispozitiv nou, GAP 9 de la Greenwaves Technologies, care vizează aceeași piață, conține un cluster de zece nuclee cu arhitectură RISC-V. Ambele companii oferă, de asemenea, un lanț complet de instrumente pentru dezvoltarea aplicațiilor bazate pe AI pentru produsele lor. Se așteaptă o explozie de cipuri de tip microcontroler, optimizate pentru TinyML, ca să apară în următorul an sau cam așa ceva. În viitor, este probabil ca AI să domine Internetul Lucrurilor. Dar nu și rasa umană, încă …
Autor: Bill Marshall
![]()
Aurocon Compec
https://www.compec.ro