

 Învățarea automată integrată în dispozitiv are potențialul de a revoluționa nenumărate produse, fie că este vorba de clasificarea obiectelor de la un senzor de imagine, a gesturilor de la un accelerometru sau a frazelor dintr-un flux audio. Însă, pentru a realiza acest lucru, algoritmii trebuie să fie executați pe componente încorporate. Dezvoltarea aplicațiilor bazate pe învățare automată necesită coordonarea mai multor discipline tehnice, dar majoritatea corporațiilor nu dispun decât de o parte din aceste discipline reprezentate la nivel intern. Astfel, este nevoie de oameni de știință, de ingineri în domeniul învățării automate și de dezvoltatori de software pentru a crea, antrena, ajusta și testa modelele pentru învățarea automată. Problema este că aceste modele nu rulează, de obicei, pe hardware încorporat sau pe dispozitive mobile, deoarece majoritatea inginerilor din domeniul învățării automate nu au mai folosit niciodată modele pe asemenea hardware și nu sunt familiarizați cu limitările de resurse. Pentru ca modelele instruite să fie utilizate pe SoC-uri mobile, FPGA-uri și microprocesoare, modelul trebuie optimizat și cuantificat.
Învățarea automată integrată în dispozitiv are potențialul de a revoluționa nenumărate produse, fie că este vorba de clasificarea obiectelor de la un senzor de imagine, a gesturilor de la un accelerometru sau a frazelor dintr-un flux audio. Însă, pentru a realiza acest lucru, algoritmii trebuie să fie executați pe componente încorporate. Dezvoltarea aplicațiilor bazate pe învățare automată necesită coordonarea mai multor discipline tehnice, dar majoritatea corporațiilor nu dispun decât de o parte din aceste discipline reprezentate la nivel intern. Astfel, este nevoie de oameni de știință, de ingineri în domeniul învățării automate și de dezvoltatori de software pentru a crea, antrena, ajusta și testa modelele pentru învățarea automată. Problema este că aceste modele nu rulează, de obicei, pe hardware încorporat sau pe dispozitive mobile, deoarece majoritatea inginerilor din domeniul învățării automate nu au mai folosit niciodată modele pe asemenea hardware și nu sunt familiarizați cu limitările de resurse. Pentru ca modelele instruite să fie utilizate pe SoC-uri mobile, FPGA-uri și microprocesoare, modelul trebuie optimizat și cuantificat.

Pentru a permite ca învățarea automată să funcționeze pe hardware încorporat, modelele trebuie cuantificate și optimizate. (© Rutronik)
La rândul lor, producătorii de semiconductori se confruntă cu sarcina de a dezvolta produse care să satisfacă noi cerințe în ceea ce privește performanța, costul și factorul de formă – toate acestea cu cerințe stricte privind timpul de lansare pe piață. Este nevoie de flexibilitate în ceea ce privește interfețele, intrările, ieșirile și utilizarea memoriei, astfel încât produsele să poată satisface o varietate de aplicații.
TensorFlow Lite simplifică optimizarea și cuantificarea
Procesul a devenit oarecum mai ușor în ultimii ani datorită TensorFlow Lite de la Google. Această platformă open source pentru învățare automată include acum scripturi ce pot fi utilizate pentru a optimiza și cuantifica modelele de învățare automată într-un fișier “FlatBuffers” (*.tflite). Acesta utilizează parametrii configurați pentru un anumit mediu de aplicații.
Ideal, un produs hardware embedded (încorporat) ar trebui să poată importa fișiere FlatBuffer direct din TensorFlow fără a fi nevoit să utilizeze metode de optimizare proprietare sau specifice hardware-ului în afara ecosistemului TensorFlow. Acest lucru permite inginerilor de software și hardware să utilizeze cu ușurință fișierul FlatBuffer cuantificat și optimizat pe FPGA-uri, SoC-uri și microcontrolere.
O comparație între SoC-uri, microcontrolere și FPGA-uri
Platformele hardware embedded dispun de resurse limitate, nu sunt deosebit de bune pentru scopuri de dezvoltare și sunt dificil de utilizat. Dar, ca recompensă, ele oferă un consum redus de putere, costuri scăzute și module cu dimensiuni compacte. Ce oferă SoC-urile, microcontrolerele și FPGA-urile?
SoC-urile oferă cea mai mare performanță și multe interfețe standard, dar, de obicei, au și cel mai mare consum de putere. În plus, intrările și ieșirile specifice interfețelor ocupă mult spațiu pe cip, ceea ce le face relativ costisitoare.
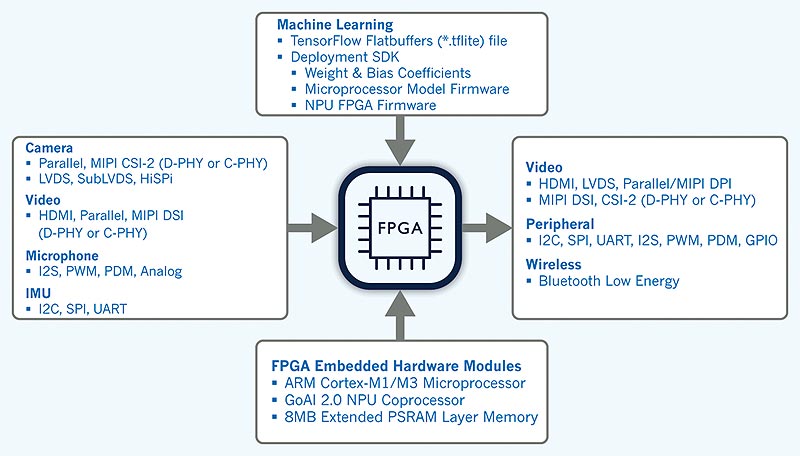
FPGA-urile oferă interfața potrivită și scalabilitate facilă pentru fiecare aplicație. (© Rutronik)
Avantajul oferit de microcontrolere este consumul foarte redus de putere și factorul de formă mic, dar acestea sunt adesea foarte limitate în privința performanțelor de învățare automată și a capacității de modelare. Modelele din gama superioară de produse oferă, de obicei, doar interfețe specializate, cum ar fi cele pentru camere sau microfoane digitale.
FPGA-urile acoperă un segment larg între microcontrolere și SoC-uri. Acestea sunt disponibile într-o gamă largă de variante constructive precum și cu intrări și ieșiri flexibile. Prin urmare, ele pot suporta orice interfață necesară pentru o anumită aplicație, fără a irosi spațiu pe cip. Opțiunile de configurare permit, de asemenea, scalarea costului și a consumului de putere în concordanță cu performanța și permit integrarea unor funcții suplimentare. Problema cu utilizarea FPGA-urilor pentru învățarea automată este lipsa de suport și de integrare pentru platformele SDK, cum ar fi TensorFlow Lite.
FPGA-uri pentru învățare automată
Pentru a depăși acest inconvenient, Gowin Semiconductor oferă un SDK pe platforma sa GoAI 2.0 care extrapolează modelele și coeficienții, generează cod C pentru procesorul ARM Cortex-M integrat în FPGA-uri și generează fluxuri de biți și firmware pentru FPGA-uri.
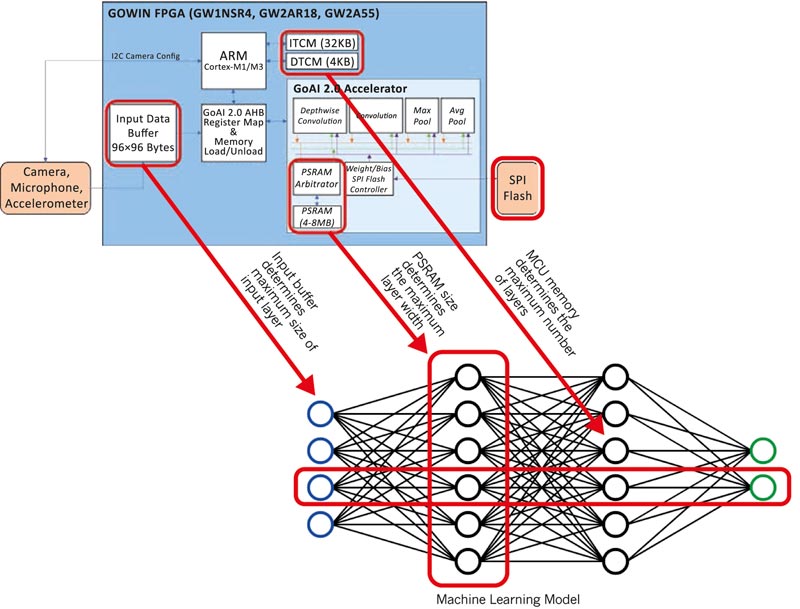
Cu memorie PSRAM suplimentară, GW1NSR4P de la Gowin oferă o extindere maximă a straturilor și, astfel, permite procesare accelerată și stocarea straturilor de tip folding și pooling. (© Rutronik)
O altă provocare constă în cerințele substanțiale de memorie flash și RAM ale modelelor de învățare automată. Noile FPGA-uri hibride µSoC, cum ar fi Gowin GW1NSR4P, satisfac aceste cerințe prin încorporarea a 4 până la 8 MB de memorie PSRAM suplimentară. GW1NSR4P oferă un coprocesor special GoAI 2.0 pentru procesare accelerată și stocare a straturilor de tip folding și pooling. Acesta este utilizat împreună cu nucleul său hardware Cortex-M IP, care controlează parametrii stratului, procesarea modelului și rezultatele de ieșire.
Mulți furnizori de dispozitive semiconductoare programabile oferă clienților, care utilizează hardware încorporat pentru învățarea automată, programe de servicii de proiectare pentru curbe de învățare mai abrupte. Gowin nu face excepție în acest caz – programul de servicii de proiectare GoAI vine în sprijinul utilizatorilor care caută o soluție pe un singur cip pentru clasificare sau pentru asistență la implementarea unor modele testate și instruite “de pe raft”, dar care nu știu cum ar trebui să comunice cu hardware-ul încorporat.
Furnizorii oferă acest tip de programe pentru a ajuta întreprinderile să utilizeze mai puține resurse în legătură cu învățarea automată încorporată și cu implementările pe hardware embedded (TinyML), astfel încât acestea să se poată concentra mai activ pe dezvoltarea produselor lor.
Concluzie
Local, învățarea automată încorporată este un domeniu popular și în continuă creștere pentru mulți dezvoltatori de produse. Totuși, există provocări considerabile, deoarece pentru dezvoltarea acestor soluții este nevoie de ingineri din diverse discipline și domenii. Unii furnizori de dispozitive semiconductoare programabile răspund acestei nevoi atât prin utilizarea unor instrumente populare ale ecosistemului pentru hardware embedded, cât și prin oferirea de dispozitive cu interfețe flexibile, memorie extinsă, noi instrumente software și servicii de proiectare.
Autori:
![]()
Zibo Su
Product Manager Digital la Rutronik
![]()
Daniel Fisher
Senior FAE EMEA la GoWin –Semiconductor
Rutronik | https://www.rutronik.com
![]()